Anthropic heeft vandaag Claude Fable 5 gelanceerd, en het is niet zomaar een update. Het bedrijf noemt het de krachtigste AI die het ooit voor iedereen beschikbaar heeft gemaakt. Bij een vroege test comprimeerde Fable 5 twee maanden engineeringwerk bij Stripe naar één dag. Het is state-of-the-art op vrijwel alle geteste benchmarks, van coderen tot wetenschappelijk onderzoek, en het kost minder dan de helft van Mythos Preview, maar twee keer zoveel als Opus 4.8. Maar er zit een twist: voor bepaalde onderwerpen schakelt het model stilletjes terug naar Opus 4.8.
Wat is Claude Fable 5 precies?
Fable 5 is het eerste model uit een nieuwe klasse die Anthropic "Mythos" noemt, boven de bestaande Opus-klasse. Het zit op het allerhoogste niveau van wat Anthropic kan bouwen. De naam komt van het Latijnse fabula ("dat wat verteld wordt"), verwant aan het Griekse mythos.
Naast Fable 5 lanceert Anthropic ook Claude Mythos 5. Dat is exact hetzelfde onderliggende model, maar dan zonder de veiligheidsbeperkingen. Mythos 5 is alleen beschikbaar voor een kleine groep cyberdefenders en infrastructuurbeheerders via Project Glasswing, in samenwerking met de Amerikaanse overheid.
Even voor de beeldvorming: Anthropic heeft in feite een model gebouwd dat zo krachtig is dat het met beveiligingen moet worden uitgerust voordat het naar het publiek mag. De onbeveiligde versie (Mythos) gaat naar cyberbeveiligers. De beveiligde versie (Fable) gaat naar jou en mij.
Hoe presteert het vergeleken met andere modellen?
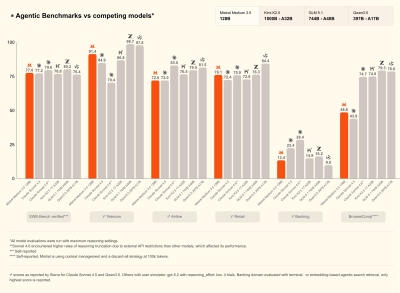
Fable 5 is state-of-the-art op bijna alle geteste benchmarks. Hoe langer en complexer de taak, hoe groter de voorsprong op andere modellen. Dat is een verschuiving: eerdere modellen waren sterk op korte taken maar verloren kwaliteit bij langlopende opdrachten.
Concrete resultaten uit de eerste tests:

- Software engineering: hoogste score op Cognition's FrontierCode, zelfs bij gemiddelde inspanning. Op CursorBench is het state-of-the-art.
- Financieel redeneren: hoogste score op Hebbia's Finance Benchmark voor senior-level analyse. IMC rapporteerde dat Fable 5 hun handelsevaluaties "bijna overal" haalde.
- Visie: het nieuwe state-of-the-art model voor visuele taken. Het kan een webapp nabouwen vanuit alleen screenshots en speelde Pokémon FireRed uit met alleen het spelscherm, zonder hulpmiddelen.
- Geheugen: bij het kaartspel Slay the Spire presteerde Fable 5 drie keer beter met persistente notities dan Opus 4.8 met dezelfde opzet.
- Wetenschap: wetenschappers verkozen Fable 5's moleculaire biologie-hypotheses in 80% van de gevallen boven die van Opus-klasse modellen.
| Capability | Claude Fable 5 | Claude Opus 4.8 | GPT-5.4 | Gemini 3.5 Flash |
|---|---|---|---|---|
| FrontierCode (codering) | Hoogste | Tweede | Derde | Vierde |
| Hebbia Finance | Hoogste | Lager | Vergelijkbaar | Niet getest |
| Visie (screenshots → code) | State-of-the-art | Met scaffolding | Vergelijkbaar | Goed |
| Lange context (miljoenen tokens) | Beste focus | Goed | Goed | Groot venster |
| Wetenschappelijke hypotheses | 80% voorkeur | 20% voorkeur | Niet getest | Niet getest |
Het indrukwekkendste voorbeeld komt uit de genomica. Mythos 5 voerde meer dan een week grotendeels zelfstandig genomisch onderzoek uit: het verzamelde single-cell data voor miljoenen cellen uit 138 diersoorten en trainde een eigen machine learning-model. Dat model presteerde beter dan een recent in het tijdschrift Science gepubliceerd model, ondanks dat het honderd keer kleiner was.
Wat betekent dit voor softwareontwikkeling?
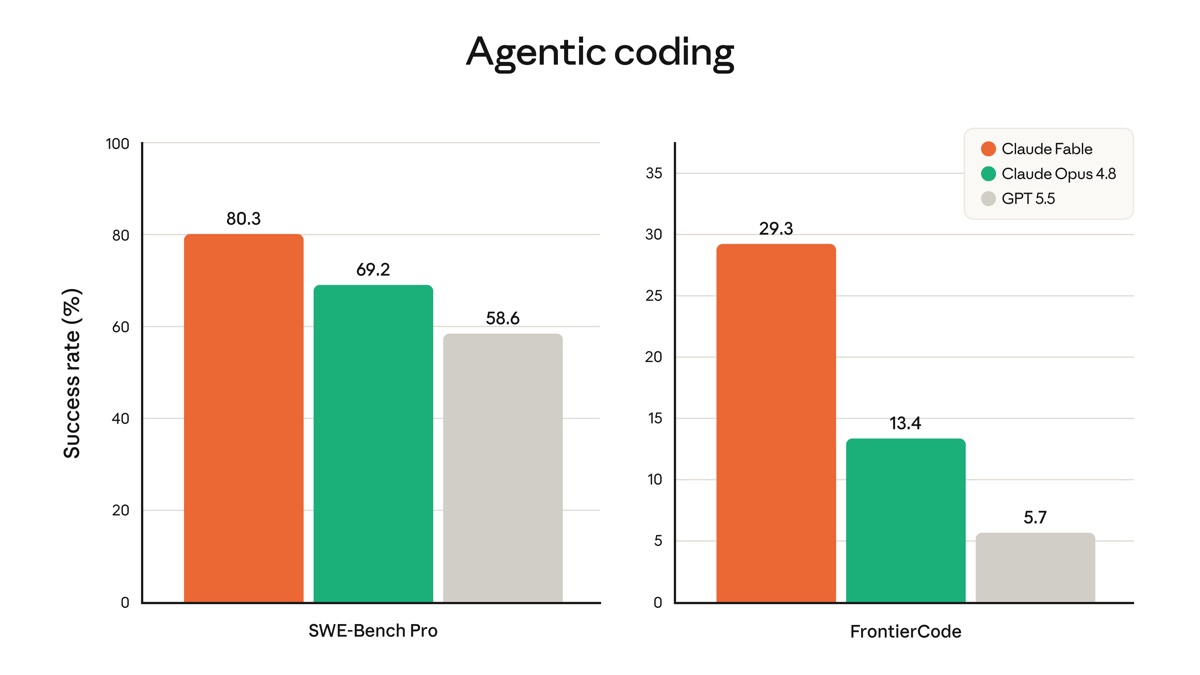
De headline-case komt van Stripe. In een codebase van vijftig miljoen regels Ruby voerde Fable 5 in één dag een volledige codebase-migratie uit waar anders een heel team meer dan twee maanden voor nodig had gehad. Dat is niet een versnelling van tien procent. Dat is een fundamenteel andere manier van werken.
Op FrontierCode, een benchmark die test of modellen moeilijke coderingstaken kunnen voltooien terwijl ze voldoen aan productiecode-standaarden, scoort Fable 5 het hoogst van alle frontier-modellen, zelfs bij gemiddelde inspanning. Dat betekent niet dat het model goedkoper is: Fable 5 denkt langer na en gebruikt daardoor meer tokens per opdracht. Maar de kwaliteit per token is hoger.
Cursor's CEO Michael Truell noemde het model "state-of-the-art op CursorBench" en zei dat het "een klasse van langlopende problemen heeft geopend die buiten bereik waren voor eerdere modellen." GitHub's Chief Product Officer Mario Rodriguez rapporteerde dat Fable 5 "complexe, langlopende coderingstaken aanpakte met een niveau van autonomie en betrouwbaarheid dat eerdere benchmarks overtrof."
“Stripe comprimeerde maanden engineering naar dagen met Claude Fable 5 in een codebase van vijftig miljoen regels.”
Anthropic blogpost, 9 juni 2026
Voor een Nederlands softwareteam dat al werkt met Claude Code is dit direct relevant. De stap van Opus 4.8 naar Fable 5 is niet een incremental upgrade. Het is het verschil tussen een AI-assistent die je moet begeleiden en een die je een opdracht kunt geven en een dag later terugkomt met het resultaat.
Waarom heet het Fable en niet Opus 5?
Anthropic introduceert met Fable een nieuwe naamgevingslaag. De modellen zijn nu geordend in klassen: Haiku (snel en goedkoop), Sonnet (balans), Opus (krachtig), en nu Mythos (frontier). Fable is de publiek beschikbare versie van een Mythos-klasse model, uitgerust met extra beveiligingen.
De analogie is bewust: Mythos is de ruwe kracht, Fable is het verhaal dat je ermee kunt vertellen. Denk aan het verschil tussen een onbewerkt diamant en een geslepen steen. Dezelfde materie, maar één is veilig om mee te werken.
Dit is ook een signaal over de richting van AI-modellen. Anthropic zegt hiermee impliciet: we bouwen nu modellen die te krachtig zijn om zonder beperkingen vrij te geven. Dat klinkt als marketing, maar de cybersecurity-tests onderbouwen het. Mythos 5 heeft de sterkste cybersecurity-capaciteiten van elk model ter wereld, en juist daarom krijgt alleen een beperkte groep verdedigers er onbeperkt toegang toe.
Wat kosten Fable 5 en Mythos 5?
Beide modellen kosten 10 dollar per miljoen inputtokens en 50 dollar per miljoen outputtokens. Omgerekend is dat ongeveer 9,20 euro en 46 euro inclusief btw, afhankelijk van de wisselkoers.
Ter vergelijking met andere modellen:
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Relatief |
|---|---|---|---|
| Claude Fable 5 | $10 (±9,20€) | $50 (±46€) | Baseline |
| Claude Opus 4.8 | $5 (±4,60€) | $25 (±23€) | Twee keer goedkoper per token |
| Claude Sonnet 4.6 | $3 (±2,76€) | $15 (±13,80€) | 70% goedkoper |
| GPT-5.4 | $10 | $30 | Vergelijkbare input, goedkopere output |
| Gemini 3.5 Flash | $0,15 | $0,60 | Veel goedkoper, minder krachtig |
Fable 5 kost per token minder dan de helft van Claude Mythos Preview (het vorige frontier-model). Maar vergeleken met Opus 4.8 is het twee keer zo duur: 10 dollar versus 5 dollar per miljoen inputtokens, en 50 dollar versus 25 dollar per miljoen outputtokens. Daar komt bij dat Fable 5 meer tokens per taak gebruikt doordat het langer nadenkt. De effectieve kosten per opdracht liggen daardoor fors hoger dan bij Opus.
Voor een mkb-er die nu de AI-prijzen van juni 2026 vergelijkt: Fable 5 is het duurste model in de Claude-lijn: twee keer de tokenprijs van Opus 4.8 en drie keer die van Sonnet 4.6. Daarbovenop gebruikt het meer tokens per antwoord. De rekening loopt dus snel op. De vraag is of de resultaten het verschil waard zijn. Voor routinetaken is Opus 4.8 de verstandige keuze. Fable 5 betaalt zich terug bij taken waar Opus tekortschiet: complexe migraties, langlopende autonome opdrachten en taken waar je anders een heel team op zet.
Wat zijn de beperkingen en beveiligingen?
Hier wordt het interessant. Fable 5 is uitgerust met een nieuw systeem van classifiers: aparte AI-systemen die potentieel misbruik detecteren. Wanneer een classifier afgaat, wordt het verzoek automatisch doorgestuurd naar Opus 4.8 in plaats van door Fable zelf beantwoord. De gebruiker krijgt hier een melding van.
De classifiers dekken drie gebieden:
- Cybersecurity. Fable 5 kan softwarekwetsbaarheden ontdekken en uitbuiten. Die capaciteit is waardevol voor verdedigers, maar gevaarlijk in verkeerde handen. Alle offensieve cybervragen worden doorgestuurd naar Opus 4.8.
- Biologie en chemie. Mythos-klasse modellen kunnen taken uitvoeren in gentherapie-onderzoek die ook misbruikt zouden kunnen worden. Voorlopig wordt het merendeel van biologie- en scheikundevragen doorgestuurd.
- Destillatie. Anthropic heeft pogingen ontdekt om Claude's capaciteiten te extraheren voor het trainen van concurrerende modellen. Verzoeken die daar op lijken, gaan naar Opus 4.8.
In de praktijk triggeren de beveiligingen in minder dan 5% van de sessies. In meer dan 95% van de gesprekken merk je er niets van en presteer je effectief op Mythos 5-niveau.
Anthropic erkent dat de beveiligingen soms te streng zijn en onschuldige verzoeken blokkeren. Het bedrijf zegt de false positives zo snel mogelijk te willen verminderen. Een extern bug bounty-programma van meer dan duizend uur leverde geen universele jailbreaks op.
Daarnaast introduceert Anthropic een nieuwe bewaarplicht: alle API-verkeer op Mythos-klasse modellen wordt dertig dagen bewaard. Het wordt niet gebruikt voor training, alleen voor veiligheidsanalyse. Na dertig dagen wordt het verwijderd.
Wanneer kun je het gebruiken en op welk abonnement?
Fable 5 is vandaag beschikbaar via de Claude API met model-ID claude-fable-5. Maar de beschikbaarheid op abonnementen is complexer dan gebruikelijk:
- API en consumption-based Enterprise: volledig beschikbaar vanaf vandaag.
- Pro, Max, Team en seat-based Enterprise: gratis inbegrepen van vandaag tot en met 22 juni. Daarna vereist het gebruik usage credits.
- Na 22 juni: Anthropic wil Fable 5 zo snel mogelijk weer standaard opnemen in abonnementen, maar garandeert dit niet. Het hangt af van de capaciteit.
Overigens is dat een opmerkelijke aanpak. Anthropic geeft iedereen twee weken gratis toegang om het model te testen, en trekt het dan terug als de vraag te groot is. Het bedrijf communiceert transparant: de vraag is moeilijk te voorspellen en ze willen liever eerder toegang geven dan te laat.
Voor een Nederlands bedrijf dat al een Claude Max-abonnement heeft (200 dollar per maand): je kunt Fable 5 nu direct gebruiken. Maar houd er rekening mee dat het na 22 juni extra kan kosten. Bekijk de Anthropic-prijspagina voor de actuele stand van zaken.
Wat maakt Fable 5 anders dan een gewone modelupgrade?
Drie dingen vallen op die breken met het gebruikelijke patroon van AI-releases:
Autonome langlopende taken. Eerdere modellen waren goed in korte interacties: een vraag, een antwoord. Fable 5 kan dagenlang zelfstandig werken aan complexe opdrachten. Het genomica-onderzoek duurde meer dan een week. De Stripe-migratie een volle dag. Dat is een kwalitatief andere capability dan "sneller antwoord geven".
Zelfcorrectie. Bij het hoogste inspanningsniveau reflecteert Fable 5 op zijn eigen werk en valideert het. Yusuke Kaji van Recruit noemt dit "wat zeer autonome operaties mogelijk maakt, het extra denken betaalt zichzelf terug." Eerder moest een mens het werk controleren. Nu controleert het model zichzelf.
De veiligheidsarchitectuur. Dit is de eerste keer dat Anthropic een model uitbrengt met een expliciet fallback-systeem naar een minder krachtig model. Het is een erkenning dat er een spanning bestaat tussen capaciteit en veiligheid die niet met één model op te lossen is. Verwacht dat andere AI-labs dit patroon gaan overnemen.
Wat kun je hier als ondernemer mee?
Vier concrete overwegingen voor deze week:
- Test Fable 5 voor je duurste taken. Als je team Claude gebruikt voor codebase-migraties, documentanalyse of financieel redeneren: probeer dezelfde taak met Fable 5 voor 22 juni. Het is gratis op je huidige abonnement en de resultaten zijn volgens de eerste testers meetbaar beter.
- Vergelijk je effectieve kosten. Fable 5 kost twee keer zoveel per token als Opus 4.8 en gebruikt bovendien meer tokens per taak. Test dezelfde opdracht op beide modellen en vergelijk de totale rekening. Gebruik Fable 5 alleen voor taken waar Opus tekortschiet.
- Houd rekening met de classifier-fallback. Als je team in de cybersecurity, biologie of chemie werkt, zal tot 5% van de verzoeken worden beantwoord door Opus 4.8 in plaats van Fable 5. Test of dat voor jouw workflow een probleem is.
- Let op de 30-daagse dataretentie. Anthropic bewaart nu alle API-verkeer op Fable 5 en Mythos 5 dertig dagen voor veiligheidsanalyse. Als je organisatie strikte privacy-eisen heeft (denk aan zorg of overheid onder de AVG), overleg met je privacy officer of dit past binnen je beleid.
De bredere les is dat de race in AI-modellen niet meer alleen over benchmarks gaat. Het gaat over hoe lang een model zelfstandig kan werken, hoe betrouwbaar de output is zonder menselijke controle, en hoe veilig je het kunt inzetten. Fable 5 is het eerste model dat op alle drie die assen tegelijk een stap vooruit zet. Voor een ondernemer die AI serieus neemt, is het de moeite waard om de komende twee weken intensief te testen.