Dezelfde antwoorden die je nu voor twintig euro per maand uit een Amerikaanse cloud trekt, maar dan vanaf een server die je zelf bezit, met data die nooit het pand verlaat. IBM bracht vorige week een 8B-model uit dat dat scenario opeens realistisch maakt. Granite 4.1 verslaat zijn eigen 32B-voorganger op tien benchmarks tegelijk, draait op hardware die je waarschijnlijk al hebt staan, en spreekt officieel ook Nederlands. Voor een zorginstelling, gemeente of advocatenkantoor dat al een jaar worstelt met de vraag waar AI-data eigenlijk heen mag, is dit het soort release dat de discussie heropent.
Wat IBM precies heeft losgelaten
Op 29 april zette IBM Research drie modellen tegelijk op Hugging Face: een 3B, een 8B en een 30B variant, allemaal dense decoder-only en allemaal onder Apache 2.0-licentie. Dat laatste detail is belangrijk. Apache 2.0 betekent dat je het model commercieel mag gebruiken, dat je het mag finetunen, en dat je het in een product kunt verpakken zonder dat IBM achteraf met een licentie-rekening voor je deur staat. Dit zijn echte open weights, niet de halfslachtige varianten die andere labs sinds vorig jaar uitbrengen onder hun eigen Acceptable Use Policy.
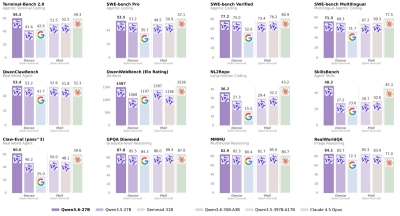
De vermelde context window: 131.072 tokens standaard, met een uitbreiding tot 512K voor specifieke deployments. De aandacht ging uit naar één claim: het 8B-model verslaat IBM's eigen 32B-voorganger op tien benchmarks tegelijk. Op BFCL v3 (tool calling) scoort de 8B 68,3 tegenover 64,7 voor de oude 32B. Op GSM8K (rekensommen) 92,5. Op HumanEval (code) 85,4. Op MMLU 73,8. Op IFEval (instructies opvolgen) 87,1. Geen frontier-cijfers, en daar zitten Claude Opus 4.7 en GPT-5.5 in een ander universum, maar voor een 8B is het opvallend. Vooral het tool calling-cijfer maakt agents-werk concreet sneller.
Waarom past een 8B in je serverkast en een 32B niet?
Hier zit de echte sprong. Een 8B-model in BF16-precisie heeft ongeveer 16 GB GPU-geheugen nodig. Dat past op een enkele Nvidia L4, een A4000, of zelfs een consumer-kaart als de RTX 4090. Praat over een werkstation van twee- tot vijfduizend euro. Een 32B-model heeft minimaal 64 GB nodig, dus twee A100's of een H100. Dat is een dertig- tot vijftigduizend euro investering, plus de bijbehorende koeling en stroom.
IBM koos bewust voor dense modellen in plaats van Mixture-of-Experts, en is daar in zijn eigen blog vrij stellig over. Distinguished engineer Rameswar Panda schrijft: "Granite 4.1 delivers competitive instruction-following and tool-calling performance without relying on long chains of thought, offering predictable latency, stable token usage, and lower operational cost." Vrij vertaald: we hebben gekozen voor wat in een serverrack past en niet voor wat goed staat in een paper. Voor enterprise-workloads is voorspelbare latency vaak belangrijker dan een extra puntje op een benchmark.
Dit is alsof je het verschil hebt tussen een auto die past in je oprit en eentje die je alleen op een vrachtwagen kunt verplaatsen. Hetzelfde voertuig, andere logistiek. En de logistiek bepaalt of het in productie kan.
Met 4-bit kwantisatie via llama.cpp brengt je het 8B-model verder terug naar ongeveer 5 GB. Dan draait het op een Mac mini M4. Letterlijk een doos van duizend euro op je bureau. Dat is niet meer "infrastructuur" in de oude betekenis, dat is een randapparaat.
Spreekt het ook echt Nederlands?
Officieel ja. IBM noemt twaalf talen in de modelkaart: Engels, Duits, Spaans, Frans, Japans, Portugees, Arabisch, Tsjechisch, Italiaans, Koreaans, Nederlands en Chinees. Nederlands staat dus expliciet in de doellijst, naast de gebruikelijke vier grote Europese talen.
Maar IBM zet er zelf een waarschuwing bij: niet-Engelse prestaties halen niet altijd het Engelse niveau, en few-shot voorbeelden in de prompt zijn aan te raden. Wees daar eerlijk over voordat je het in productie zet. Voor zoekopdrachten, samenvatten en classificatie van Nederlandstalige tekst werkt het. Voor het schrijven van juridisch perfecte Nederlandstalige output zonder voorbeelden: dat moet je zelf testen op je eigen documenten, niet op IBM's woord vertrouwen.
Vergelijking met de frontier: Claude en GPT-5.5 zijn nog steeds beter in NL, getraind op enorm veel meer Europese tekst. Maar voor 90% van de interne use-cases die NL-bedrijven hebben, zoals mailen samenvatten, tickets classificeren, kennisbank doorzoeken en FAQs genereren, is een open model goed genoeg. En "goed genoeg" combineren met "blijft op je eigen server" verandert het hele gesprek.
Wat dit voor je AVG-werk doet
Hier is het echte verkoopargument voor Nederlandse organisaties. Sinds de AI Act en de versterkte AVG-handhaving zit elke DPO klem met dezelfde discussie: data-doorgifte naar de VS, Cloud Act-blootstelling, DPIA's die niet rondkomen. De Autoriteit Persoonsgegevens heeft hier meermaals over gewaarschuwd. Bij ziekenhuizen komt NEN 7510 erbovenop, bij gemeenten BIO 2.0, bij OM en politie de Wet politiegegevens.
On-premise inference is het simpelste antwoord op die hele stapel. Geen cloud-doorgifte, geen DPIA-zorgen rond een Amerikaanse provider, geen vendor lock-in. Je hebt nog steeds een verwerkingsregister nodig, je moet nog steeds toegang afdichten, je moet nog steeds beoordelen of de dataset waarop het model is getraind acceptabel is. Maar het juridische zwaartepunt verschuift van "doorgifte naar derde land" naar "interne verwerking", een veel makkelijker gesprek.
Even afstand nemen. On-premise heeft eigen risico's. Jij moet de hardware onderhouden. Jij moet patches doorvoeren. Jij moet inferentie-prestaties tunen als de load groeit. Geen Anthropic-team dat dat voor je oplost. Voor een MKB-er zonder ML-engineer in huis is dat een serieuze drempel, al zijn er steeds meer Nederlandse partijen (TNO, SURF, lokale system integrators) die dit als dienst aanbieden.
Voor zorginstellingen speelt nog iets extras. De recente AP-uitspraken over generatieve AI in de zorg leggen de bal expliciet bij de organisatie zelf: jij bent verwerkingsverantwoordelijke, jij moet aantonen waar de data heen gaat. Met de tien Nederlandse loketten die straks de AI Verordening gaan handhaven wordt die last alleen maar zwaarder. Een lokaal model is dan niet de duurste, maar de simpelste keuze. Geen jaarlijks gevecht over een nieuwe versie van een verwerkersovereenkomst.
Wanneer is on-premise het waard, en wanneer is een API gewoon makkelijker?
Niet voor elk bedrijf de juiste keuze. On-premise loont als je in minstens één van deze situaties zit: data mag echt niet uit huis (zorg, financiële sector, overheid, juridisch), je hebt veel volume waar API-kosten oplopen (boven het miljoen tokens per dag begint het ergens te knijpen), of je use-case vereist geen frontier-redenering. Denk aan klassieke RAG, classificatie, extractie, samenvatten.
API blijft beter als je incidenteel zware redenering nodig hebt, als je geen ML-engineer in huis hebt om het te beheren, of als je use-case juist wel frontier-prestaties vereist (complexe code-refactors, ingewikkelde juridische analyse). Voor die taken is het abonnementsmodel van Anthropic en OpenAI nog steeds het simpelste pad.
Concrete kostenvergelijking voor een MKB-er met vijftig medewerkers. ChatGPT Plus is €22 per gebruiker per maand. Vijftig man komt op €1.100 per maand of €13.200 per jaar. Een Granite-server kost eenmalig vijf- tot vijftienduizend euro hardware, plus pakweg honderd euro stroom per maand en, als je het uitbesteedt, een paar honderd euro beheerskosten per maand. Twee jaar afschrijving zit in de buurt van één jaar Plus-abonnementen. Het is geen no-brainer, maar het is ook geen onhaalbare droom meer. Het kantelpunt is verschoven.
Wat het niet kan
Eerlijk zijn: Granite 4.1 is geen GPT-5.5 en geen Claude Opus 4.7. Voor complex code-redeneerwerk waarbij het model meerdere bestanden tegelijk in zijn hoofd moet houden, blijft Claude voorlopig sterker. Lange redeneringsketens in thinking-mode-stijl zijn er ook niet. IBM heeft expliciet gekozen voor "thinking disabled" als default, omdat ze juist mikken op voorspelbare latency en stabiel tokenverbruik. Dit is geen reasoning model. Multimodaal werk in beeld of audio gaat ook niet via deze 8B; daarvoor is er een aparte Granite Vision 4.1.
Granite is een werkpaard, geen showpaard. Ideaal voor de saaie, schaalbare taken die in elke organisatie 80% van het AI-werk vormen: tickets categoriseren, e-mails samenvatten, knowledge base doorzoeken, formulieren extraheren. Niet voor "schrijf mijn pitch deck", "los deze ingewikkelde codebase op" of "doe een complex juridisch advies".
Wat dit nu betekent voor de keuzes op tafel
Ben je betrokken bij een AI-tool-selectie in je organisatie? Zet Granite 4.1 expliciet op de longlist naast Claude, GPT en Mistral. Niet omdat het wint op prestaties, maar omdat het de discussie over data-residency in één klap eenvoudiger maakt. Ben je IT-architect? Download via Ollama (één commando), draai het lokaal en stel een interne benchmark op tegen je eigen NL-data: drie use-cases die je nu al via een API doet. Vergelijk output, vergelijk latency, vergelijk kosten.
Ben je DPO of compliance officer? Granite verandert het kostenargument waarmee je tot nu toe terugviel op "we accepteren ChatGPT omdat lokaal te duur is". Dat argument verzwakt nu, en je kunt erop wachten dat de jurist die jouw DPIA ondertekent het ook gaat opmerken.
Komende weken zijn er twee dingen om in de gaten te houden. Of Mistral met een vergelijkbaar 8B-tegenwicht komt. De Europeanen kunnen zich een achterstand op open-source efficiency niet veroorloven. En of de Nederlandse pleitbezorgers van AI-soevereiniteit (TNO, SURF, NLAIC) Granite oppakken als referentie-model voor de lokale POCs die ze al een jaar lang adviseren. Een 8B-model dat het werk van een 32B doet en ook nog onder Apache 2.0 staat, verandert het gesprek over "AI in eigen huis" van fictie naar planbare optie. Niet de oplossing voor elk probleem. Maar voor de organisaties die al een jaar wachten op een acceptabele on-premise route. Dit is het signaal waar ze op stonden te wachten.
Meer van dit soort keuzes wegen we elke werkdag voor je in onze dagelijkse AI-nieuwsbrief: één e-mail, primaire bronnen, NL-vertaling van wat het voor jouw werk betekent.