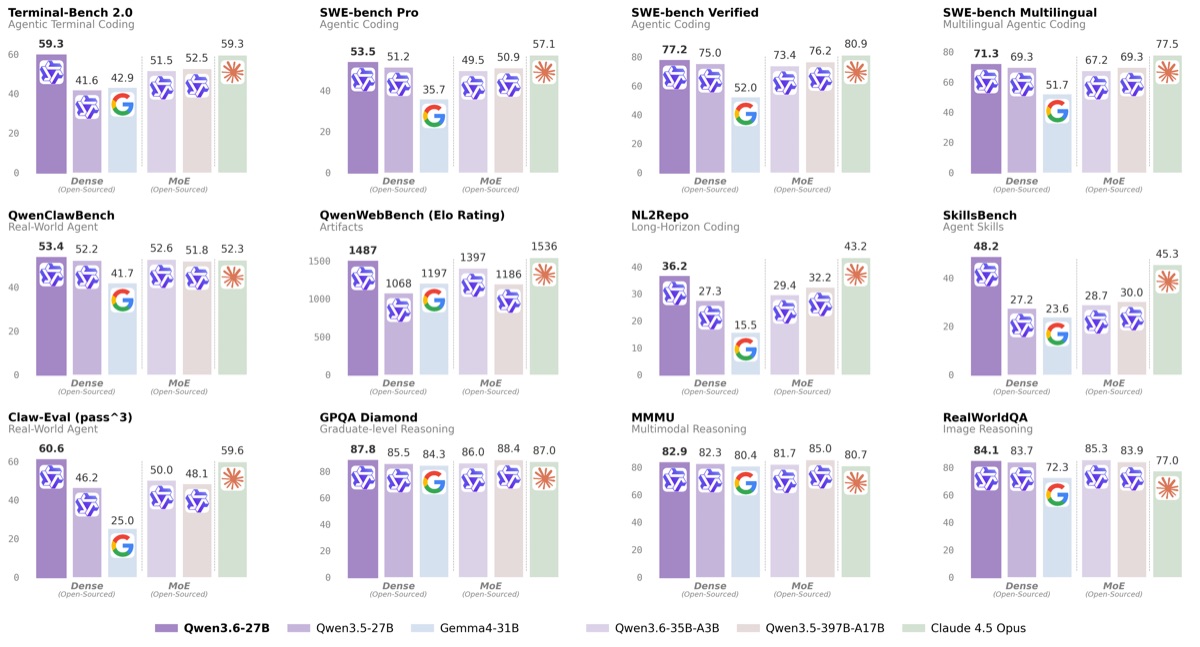
Alibaba's Qwen-team heeft op 22 april 2026 een open dense model van 27 miljard parameters uitgebracht dat op vrijwel elke coding-benchmark hoger scoort dan zijn eigen voorganger met 397 miljard totale parameters. Qwen 3.6-27B haalt 77,2 punten op SWE-bench Verified en 59,3 op Terminal-Bench 2.0, in lijn met Claude Opus 4.7. Het model staat onder Apache 2.0 op Hugging Face, past in een enkele H100-GPU en mag dus binnen een Nederlands datacenter draaien. Voor zorginstellingen, banken en overheidsorganisaties die generatieve AI tot nu toe op cloud-API's beperkten omdat ze data niet over de grens mogen sturen, is dit het eerste open model dat de coding-prestaties van een betaalde topdienst evenaart.
De cijfers, eerlijk bekeken
Op SWE-bench Verified scoort Qwen 3.6-27B 77,2 tegen 76,2 voor de Qwen 3.5-397B-A17B-versie van afgelopen najaar. Op SWE-bench Pro 53,5 versus 50,9. Op Terminal-Bench 2.0 59,3 tegen 52,5, en op de interne SkillsBench springt het verschil naar 48,2 versus 30,0. Eén belangrijke nuance, want de cijfers zijn iets minder spectaculair dan de marketing suggereert: het oudere 397B-model is een Mixture of Experts dat per token maar 17 miljard parameters activeert. De "veertien keer groter"-claim slaat op de totale grootte op disk, niet op de actieve rekenkracht per inference-stap. De vergelijking blijft toch interessant, want het 397B-model heeft veel meer geheugen nodig om in te laden en levert daarmee minder rendement per geïnvesteerde gigabyte VRAM.
In categorieën buiten code is het beeld minder overtuigend. Op GPQA Diamond komt Qwen 3.6-27B uit op 87,8, een respectabel cijfer maar geen doorbraak. Voor agentic coding-taken is dit echter het sterkste kleine open model van dit moment.
Wat onder de motorkap zit
Twee technische keuzes vallen op. Ten eerste een hybride architectuur die Gated DeltaNet (een lineaire-attention-laag die geheugen schaalt met de sequentielengte in plaats van kwadratisch) afwisselt met klassieke self-attention. Daardoor blijft de geheugendruk bij langere prompts beheersbaar. Ten tweede een mechanisme dat het Qwen-team Thinking Preservation noemt: tussenliggende redeneringen blijven over meerdere agent-stappen behouden, zodat het model in multi-turn workflows zijn context niet kwijtraakt zoals voorgaande Qwen-modellen wel deden.
De context window is 131.072 tokens, voldoende voor een complete codebase van middelmatige omvang of een lange agentic-sessie. Het model staat onder Apache 2.0 zowel op Hugging Face als in de officiële Qwen-repository, met gewichten die je commercieel mag gebruiken zonder royalty-verplichting.
Wat het kost om dit zelf te draaien
Een 27B-model in 16-bit precisie heeft circa 54 GB geheugen nodig, wat past op een H100-GPU met 80 GB. In FP8 of INT8 zakt dat naar ongeveer 27 GB, ruim binnen een A100-40GB. Bij Hetzner staat een H100-instance op ongeveer 2,40 euro per uur, bij OVH Nederland en Leaseweb in dezelfde orde. Wie zo'n machine 24 uur per dag draait, betaalt rond de 1.700 euro per maand inclusief BTW. Een team dat nu meer dan 1.500 euro per maand aan API-credits voor Claude Opus 4.7 uitgeeft voor coding-taken, kan dus al gunstig uitkomen met een eigen instance, mits de workload constant genoeg is om de GPU bezig te houden.
Voor wie eerst wil testen zonder eigen hardware: het model staat ook bij Hugging Face Inference Endpoints en op Together AI tegen tarieven die onder de helft liggen van wat Anthropic of OpenAI rekenen voor hun topmodellen. Onze prijssnapshot van vorige week liet zien dat Opus 4.7 momenteel het duurste model in de markt is, en die prijsdruk-van-onderaf gaat de komende maanden alleen maar toenemen.
Voor welke Nederlandse situaties dit iets verandert
Drie scenario's springen eruit, allemaal afkomstig uit gesprekken die ik de afgelopen maanden voerde met klanten die wél met AI willen werken maar niet met cloud-LLM's mochten:
- Zorginstellingen met patiëntdata onder de WGBO en AVG mogen die data niet zomaar door een Amerikaans cloud-API laten verwerken, ook niet als het gehost is in een EU-region. Een lokaal te draaien model dat goed genoeg is voor coderen of voor het samenvatten van interne documentatie haalt een blokkade weg die er anderhalf jaar zat.
- Banken en verzekeraars die onder DORA en NIS2 vallen, moeten kritieke ICT-leveranciers contractueel beperken en de impact van een uitval van een externe dienstverlener kunnen aantonen. Een eigen model in eigen datacenter is een veel kortere DPIA dan een Anthropic-account met BAA en een third-country-data-transfer-clausule.
- Rijksoverheid en gemeenten zitten in dezelfde positie. De Uitvoeringswet AI-verordening waar het kabinet vorige week de consultatie voor opende, drukt nog wat extra eisen op publieke instellingen die GPAI-modellen voor besluitvorming gebruiken. Een open Apache 2.0-model met inzichtelijke gewichten is op die punten makkelijker te verantwoorden dan een gesloten API.
In alle drie gevallen ging het tot nu toe om een kostenkwestie en een kwaliteitskwestie. Op kosten was open source al vaak gunstiger; op kwaliteit zat er een gat. Dat gat is op coding-taken nu kleiner geworden.
Wat het model nog niet kan
Het zou oneerlijk zijn om dit als een Claude-killer te brengen. Op brede taken als reasoning over lange wetenschappelijke teksten, complexe vision-input of nuance in lange dialogen blijft Claude Opus 4.7 of GPT-5.5 voorlopig sterker. Qwen 3.6-27B is geen multimodaal vlaggenschip dat alles overneemt, maar een specialistisch coding-werkpaard. Voor klantenservice-bots, juridische analyse of marketing-copy kies je dit model nog niet als eerste optie.
Ook de operationele realiteit verschilt. Een eigen GPU-instance betekent monitoring, autoscaling, model-updates en een incident-response-team voor de uren dat de inference-dienst stilvalt. Wie dat liever niet zelf bouwt, betaalt het abonnementsbedrag bij een grote provider en accepteert de afhankelijkheid die daarmee komt. Voor bureaus en MKB-organisaties zonder eigen ML-platform-team blijft een API meestal de pragmatische keuze.
Waarom dit nu speelt
Gemma 4 deed het twee weken geleden voor op een ander deel van de markt: een 12B-model van Google verslaat veel grotere modellen op brede benchmarks. DeepSeek V4 Pro evenaarde Claude tegen 14 procent van de prijs. Nu legt Alibaba een derde steen op die stapel, specifiek voor coding. Drie verschillende open- of laaggeprijsde labs, drie verschillende benchmarks, één patroon: het rendement van pure schaal vlakt af, en het rendement van slimmere architectuur en betere training-data trekt aan.
Voor Nederlandse organisaties die hun AI-strategie nog moeten kiezen, betekent dit dat de standaard-aanname "we nemen Claude of GPT en betalen wat het kost" niet meer vanzelfsprekend de juiste is. De afweging tussen een open model in een eigen omgeving en een gesloten API in een Amerikaans cloud-account is op coding-werk inmiddels een echte keuze geworden. Voor compliance-gevoelige sectoren is die keuze nu makkelijker uit te leggen aan een raad van toezicht dan een half jaar geleden, en voor de rest van het MKB tikt de uitlegbaarheids-klok van de AI Act-deadline ondertussen door.



