
Een kleiner model dat het grotere model verslaat en vier keer sneller draait dan alles wat de concurrentie biedt. Dat is de pitch waarmee Google gisteren Gemini 3.5 Flash lanceerde op I/O 2026. De benchmarks zijn indrukwekkend, de prijs is laag en het model is direct beschikbaar. Voor developers en bedrijven die AI via een API aanroepen, is dit het soort release dat je rekenmachine verandert.
Wat maakt 3.5 Flash anders dan vorige versies?
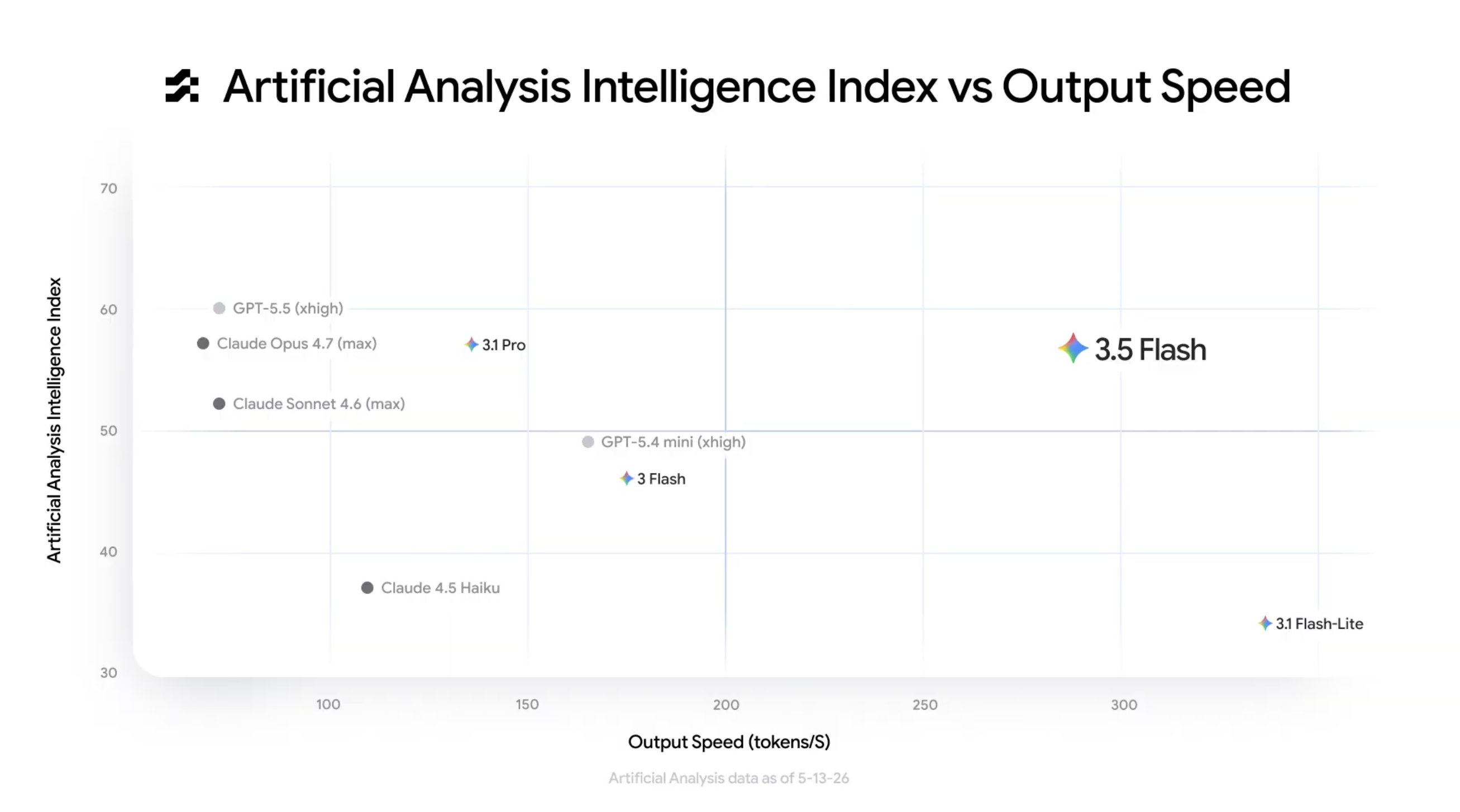
Gemini 3.5 Flash is een "Flash"-model, ontworpen voor snelheid en lage kosten. Maar waar eerdere Flash-versies duidelijk inferieur waren aan de grotere Pro-modellen, keert 3.5 Flash die verhouding om. Het model scoort hoger dan Gemini 3.1 Pro op coding, agentic taken en multimodale benchmarks. Een kleiner, goedkoper model dat het grotere model inhaalt.
De specifieke cijfers:
- Terminal-Bench 2.1 (codering): 76,2 procent, hoger dan 3.1 Pro
- MCP Atlas (agentic tool use): 83,6 procent
- CharXiv Reasoning (multimodaal): 84,2 procent
- Artificial Analysis index: top-3 van 116 modellen in agentic tool use met een score van 97,3
Dat zijn geen marginale verbeteringen. Op de agentic benchmarks staat 3.5 Flash in de top drie van alle modellen wereldwijd, naast Claude Opus en GPT-5. En het draait vier keer sneller.
Hoe snel is vier keer sneller?
Google claimt dat 3.5 Flash "vier keer meer output tokens per seconde genereert dan andere frontier-modellen." In de praktijk betekent dat: een antwoord dat bij Claude Opus vier seconden kost, is bij 3.5 Flash in een seconde klaar. Voor een chatgesprek merk je dat nauwelijks. Maar voor een API-applicatie die honderden verzoeken per minuut verwerkt, is het verschil tussen een werkende en een onwerkbare dienst.
Denk aan een klantenservice-chatbot die tijdens piekmomenten vijfhonderd gesprekken tegelijk voert. Of een code-review-agent die elke pull request in je repository analyseert. Bij die volumes telt elke milliseconde.
Wat kost het vergeleken met Claude en GPT?
Hier wordt het concreet. De prijzen per miljoen tokens (afgerond naar euro's bij de huidige wisselkoers):
- Gemini 3.5 Flash: $1,50 input / $9,00 output ($0,15 gecached)
- Claude Sonnet 4.6: $3,00 input / $15,00 output
- GPT-5: $2,00 input / $8,00 output
- Claude Opus 4.7: $15,00 input / $75,00 output
Gemini 3.5 Flash is de goedkoopste van het stel, met de helft van de inputkosten van Claude Sonnet en vergelijkbare outputkosten als GPT-5. De gecachte inputprijs van vijftien cent per miljoen tokens is opmerkelijk: als je dezelfde context herhaaldelijk meestuurt, zoals bij een chatbot met een vast systeemprompt, betaal je bijna niks voor de herhaalde tokens.
Overigens heeft Google ook de consumentenabonnementen herpriced. AI Ultra ging van 250 naar 100 dollar per maand. Dat is een patroon: Google duwt de prijzen omlaag op alle fronten.
Wat zit er onder de motorkap?
Een paar technische details die ertoe doen als je het model gaat gebruiken:
- Context window: 1 miljoen input tokens, 64.000 output tokens. Dat is genoeg om een compleet boek mee te sturen als context.
- Modaliteiten: tekst, afbeeldingen, audio en video als input. Alleen tekst als output (voorlopig).
- Dynamic thinking: standaard ingeschakeld. Het model denkt eerst na voordat het antwoordt, vergelijkbaar met wat Claude "extended thinking" noemt.
- Tool use: function calling, structured output, search-as-a-tool en code execution. Alles wat je nodig hebt om een agent te bouwen.
Die combinatie van snelheid, multimodaliteit en agentic capabilities verklaart waarom Google het model onder de motorkap van Gemini Spark heeft gestopt. Spark heeft een model nodig dat snel genoeg is om vierentwintig uur per dag taken uit te voeren zonder dat de kosten uit de hand lopen. 3.5 Flash is dat model.
Wie gebruikt het al?
GitHub was er snel bij. Gisteren kondigde GitHub aan dat Gemini 3.5 Flash beschikbaar is in GitHub Copilot voor Business en Enterprise. Dat is opvallend, omdat GitHub tot voor kort volledig op OpenAI-modellen draaide. Het feit dat ze nu een Google-model aanbieden naast GPT zegt iets over hoe competitief de markt is geworden.
Binnen Google zelf draait 3.5 Flash in de Gemini-app, in Google Search AI Mode en in de enterprise-platformen. Het model werkt met wat Google "Antigravity" noemt: een harnas dat meerdere subagents coordineert voor complexe taken. Dat is de technologie die Spark aandrijft.
Wat betekent dit voor jouw API-rekening?
Als je nu Claude of GPT via de API gebruikt, is dit het moment om je kosten te herberekenen. Een concreet voorbeeld: stel je draait een samenvattings-agent die dagelijks honderd documenten van elk tienduizend tokens verwerkt.
- Met Claude Sonnet 4.6: 1 miljoen input tokens x $3,00 = $3,00 per dag
- Met Gemini 3.5 Flash: 1 miljoen input tokens x $1,50 = $1,50 per dag
- Met caching (vaste prompt): 1 miljoen input tokens x $0,15 = $0,15 per dag
Dat is een verschil van 90 tot 95 procent als je caching optimaal inzet. Per maand scheelt dat tientallen tot honderden euro's, afhankelijk van je volume.
Er is een kanttekening. Benchmarks vertellen niet het hele verhaal. Claude is nog steeds sterker in lange, genuanceerde teksten. GPT-5 heeft een groter ecosysteem aan integraties. Flash is het beste in taken die snelheid en schaalbaarheid vereisen: classificatie, extractie, samenvattingen, agent-stappen. Kies het model dat past bij de taak, niet het model dat het goedkoopst is.
Moet je nu overstappen?
Niet per se. Maar het is wel het moment om 3.5 Flash te testen naast je huidige model. Het is direct beschikbaar via de Gemini API. Maak een gratis Google AI Studio-account aan, stuur dezelfde prompts die je nu naar Claude of GPT stuurt, en vergelijk de resultaten. Dat kost je een uurtje en nul euro.
Als de kwaliteit vergelijkbaar is voor jouw use case en de snelheid beter, heb je je antwoord. Het is geen loyaliteitskwestie. Het is rekenen. En Google heeft net de som een stuk interessanter gemaakt.



