Tussen twee sessies in kijkt je AI-agent zijn eigen werk terug, herkent fouten en schrijft de lessen op voor de volgende keer. Dat is de kern van Claude Dreaming, de feature die Anthropic dinsdag lanceerde tijdens de Code with Claude-conferentie in San Francisco. Bij juridisch AI-platform Harvey steeg het slagingspercentage van agents met factor zes, puur doordat institutionele kennis niet meer verloren ging. Het concept is simpel, maar de implicaties zijn groot: AI-agents die na elke sessie iets slimmer worden zonder dat jij ze opnieuw hoeft te trainen.
Claude Dreaming is een Anthropic-feature waarbij AI-agents tussen sessies hun eigen werk terugkijken, fouten herkennen en de lessen opslaan in plain-text bestanden. De volgende sessie leest de agent die bestanden en maakt dezelfde fout niet meer. Bij Harvey steeg het slagingspercentage met factor zes.
Waarom je agents steeds dezelfde fouten maken
De meeste AI-agents die bedrijven vandaag bouwen hebben een vervelende eigenschap: ze beginnen elke sessie met een leeg werkgeheugen. Je klantenservice-agent ontdekt na twintig gesprekken dat retourklachten altijd een ordernummer nodig hebben. De sessie eindigt. Alles weg.
Dat probleem heeft Anthropic eerder deels opgelost met Memory voor Managed Agents. Daarmee kan een agent tijdens het werken notities opslaan die hij later terugvindt. Maar memory alleen is niet genoeg.
Na honderden sessies groeit het geheugen uit tot een rommelige la vol duplicaten, verouderde instructies en tegenstrijdige aantekeningen. Je agent heeft inmiddels drieduizend notities, maar de helft is achterhaald en de relevante kan hij niet meer vinden tussen de ruis. Het is alsof je een nieuw teamlid een ordner van driehonderd pagina’s in zijn handen drukt, zonder inhoudsopgave.
Dreaming lost dat op. Het is de nachtploeg die de la opruimt.
Wat doet Claude Dreaming precies?
Denk aan een medewerker die op vrijdagmiddag de notities van zijn hele week naast elkaar legt, de rode draad eruit haalt en een opgeruimde samenvatting maakt voor maandag. Dat doet Dreaming voor je AI-agent.
Concreet is een dream een asynchrone achtergrondtaak die je via de Anthropic API start. Je geeft twee dingen mee:
- Een bestaande memory store: de plek waar je agent zijn geleerde lessen bewaart
- Optioneel tot honderd sessie-transcripten: de volledige gesprekken die je agent eerder heeft gevoerd
Claude leest alles door en doet vier dingen.
Het voegt duplicaten samen. Als je agent in sessie 12 en sessie 47 allebei heeft opgeschreven dat “de retourprocedure een ordernummer vereist”, wordt dat één entry.
Het vervangt verouderde informatie. Als de retourprocedure vorige maand is gewijzigd en je agent dat in sessie 80 ontdekte, verdwijnt de oude versie.
Het herkent nieuwe patronen die pas zichtbaar worden als je tientallen sessies naast elkaar legt. Misschien stellen klanten in de avonduren systematisch andere vragen dan overdag. Dat zag je nooit in een enkele sessie, maar over vijftig sessies heen springt het eruit.
En het herstructureert het geheugen zodat de belangrijkste lessen bovenaan staan en de randgevallen eronder.
Het resultaat is een nieuwe, aparte memory store. Dat is belangrijk: je origineel wordt niet gewijzigd. Je kunt het resultaat eerst bekijken, vergelijken met het origineel en pas dan beslissen of je het wilt activeren. Bevalt het niet? Gooi de output weg en je agent merkt er niks van.
Anthropic kiest de analogie met menselijk dromen bewust. Net zoals je brein ’s nachts herinneringen consolideert, verbanden legt en onbelangrijke details laat vallen, doet Dreaming hetzelfde met je agent-memory. Of dat meer is dan een marketingvergelijking? Daar komen we zo op.
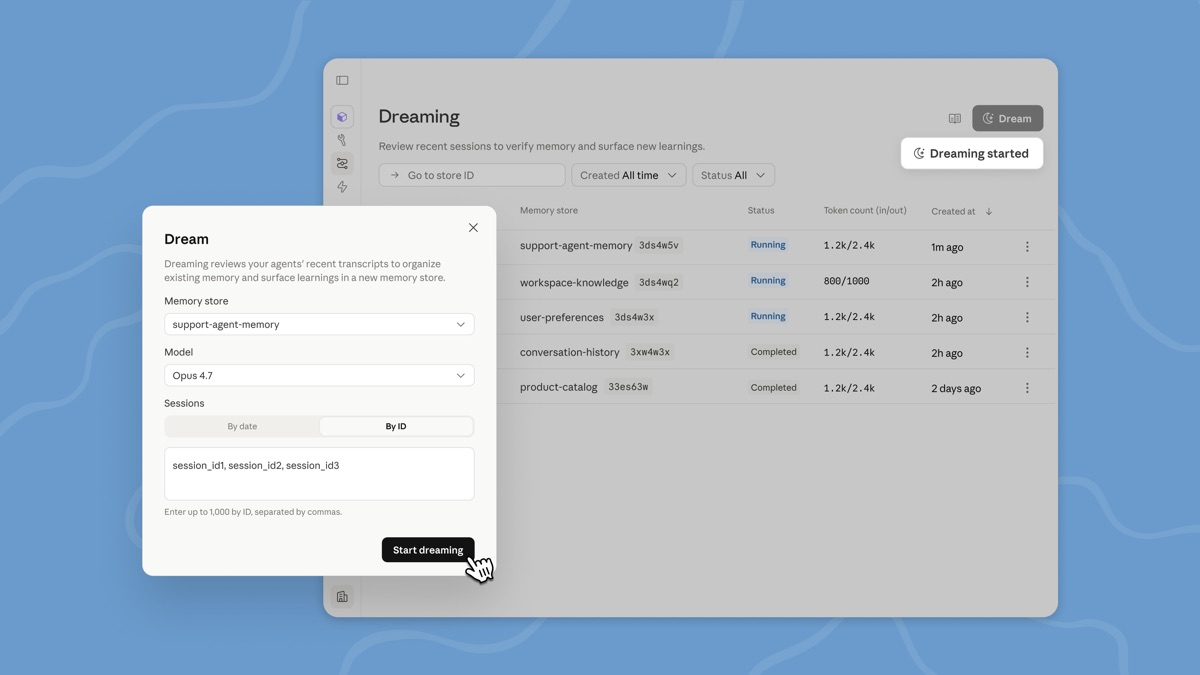
Hoe zet je een dream op?
Technisch start je een dream met een POST-request naar /v1/dreams. Je kiest een model (Claude Opus 4.7 voor de meest grondige analyse, of Sonnet 4.6 als je op kosten wilt letten), wijst een memory store toe en voegt optioneel sessie-ID’s toe.
Een vereenvoudigd voorbeeld:
POST /v1/dreams
{
"model": "claude-sonnet-4-6",
"memory_store_id": "mem_abc123",
"session_ids": ["sess_001", "sess_002", "sess_020"],
"instructions": "Focus op patronen in klantvragen over retouren"
}Het instructions-veld is optioneel maar krachtig. Je kunt het model sturen: “focus op patronen in klantvragen over retouren” of “consolideer alleen entries over API-integraties”. Maximaal 4.096 tekens.
Twee API-headers zijn verplicht die je makkelijk over het hoofd ziet. Naast de standaard managed-agents-2026-04-01 header heb je ook dreaming-2026-04-21 nodig. Zonder die tweede header weigert de API je request.
De looptijd hangt af van de hoeveelheid input. Tien sessies: een paar minuten. Honderd sessies: tientallen minuten. Je hoeft er niet op te wachten. De taak draait op de achtergrond en je checkt de status met een GET-request op /v1/dreams/{dream_id} wanneer het je uitkomt. De response bevat een usage-object met het exacte tokenverbruik, zodat je de kosten kunt volgen.
In de praktijk wil je Dreaming waarschijnlijk periodiek laten draaien. Een wekelijkse cron-job die een dream start over alle sessies van de afgelopen zeven dagen is een logische opzet. Sommige organisaties draaien het dagelijks, andere tweewekelijks. Begin met wekelijks en pas aan op basis van hoe snel je memory groeit.
Eén tip die terugkomt bij vroege gebruikers: geef je dream gerichte instructies. Een dream zonder instructies consolideert alles, maar een dream met de instructie "focus op klantcommunicatiepatronen en negeer technische debuglogs" levert een schoner en bruikbaarder resultaat op. Hoe specifieker je instructie, hoe relevanter de output.
Even voor de beeldvorming: het is niet zo dat Claude letterlijk droomt. Onder de motorkap draait er een gespecialiseerde Claude-instantie die je sessie-transcripten systematisch doorleest, patronen extraheert en je memory curateet. De naam is marketing. De functionaliteit is echt.
Dreaming is momenteel een Research Preview. Dat betekent twee dingen. Je moet via een formulier op claude.com toegang aanvragen voordat je de API-endpoints kunt gebruiken. En Anthropic behoudt zich het recht voor om breaking changes door te voeren, met minimaal een week vooraankondiging. Lees de officiële documentatie voor de meest actuele specificaties.
Het verschil tussen Memory en Dreaming
Memory en Dreaming zijn twee lagen van hetzelfde systeem, maar ze doen fundamenteel iets anders.
Memory vangt op wat een agent leert tijdens het werken. Je agent helpt een klant, ontdekt dat de retourprocedure sinds vorige maand is gewijzigd en slaat dat op. Dat is real-time, reactief en beperkt tot wat er in die ene sessie gebeurt.
Dreaming verfijnt die memory tussen sessies. Het kijkt over tientallen sessies heen, trekt gedeelde patronen eruit en verwijdert wat niet meer klopt. Dat is reflectief en proactief.
Wacht even, is dat niet gewoon een dure manier om samenvattingen te maken? Die vraag werd op Hacker News direct gesteld. Eén commentator was niet mild: “The reliance on words like ‘dreaming’ are a cynical marketing ploy to try to make the product seem more human.”
Eerlijk is eerlijk: technisch is het een vorm van gestructureerde samenvatting. Maar het verschil zit in twee dingen.
Ten eerste de scope. Een samenvatting comprimeert één sessie. Dreaming kijkt naar verbanden over tientallen sessies heen en herkent patronen die in geen enkele individuele sessie zichtbaar zijn. Misschien gebruikt je agent bij PDF-verwerking steeds dezelfde workaround die je nooit expliciet hebt geprogrammeerd. Of misschien bevatten klachten op maandagochtend drie keer zo vaak het woord “haast” als op vrijdagmiddag. Dat soort inzichten ziet een enkele sessie niet.
Ten tweede de opschoning. Dreaming verwijdert actief verouderde informatie. Als je agent in sessie 5 leerde dat de API-key in het config-bestand staat, maar in sessie 40 bleek dat die is verhuisd naar een environment variable, dan vervangt Dreaming de oude entry. Een simpele samenvatting zou beide naast elkaar bewaren en je agent later verwarren met tegenstrijdige instructies.
Claude Code droomt ook, maar anders
Als je Claude Code gebruikt, de CLI-tool voor developers, dan ken je misschien al een verwante feature: Auto-Dream. Die werkt lokaal op je machine en consolideert je memory-bestanden.
Het verschil is significant.
Claude Code Auto-Dream draait lokaal en gratis op je eigen machine. Het activeert automatisch na 24 uur inactiviteit en minimaal vijf nieuwe sessies. Het werkt op je persoonlijke memory-bestanden in ~/.claude/ en volgt een vierfasenproces: de huidige memory scannen, signalen verzamelen uit sessie-transcripten (correcties, herhalende thema’s, belangrijke beslissingen), entries samenvoegen en opschonen, en ten slotte de index bijwerken.
Managed Agents Dreaming draait daarentegen in de cloud via de API. Je start het zelf, handmatig of via een cron-job. Het werkt op gedeelde memory stores die meerdere agents tegelijk kunnen lezen. En het kost tokens, net als elk ander API-request.
Overigens kun je in Claude Code ook handmatig een dream triggeren door simpelweg “dream” te typen in je terminal. Een ontwikkelaar meldde dat 913 sessies in acht tot negen minuten werden geconsolideerd. Niet slecht voor een operatie die je volledige leergeschiedenis doorleest.
Wat doet Auto-Dream concreet? Het scant je memory-directory, leest je MEMORY.md-index, doorzoekt recente sessie-transcripten op correcties en herhalende thema's, merget dubbele entries, verwijdert verouderde pointers, en zet relatieve datums om naar absolute (zodat “vorige week” niet na twee maanden onbruikbaar wordt). Het resultaat: een opgeschoonde memory die compact en actueel blijft, zelfs als je honderden sessies achter de rug hebt.
De twee systemen delen hetzelfde principe: reflectie op eerder werk levert betere prestaties op. Het verschil zit in de schaal. Claude Code Auto-Dream optimaliseert jouw workflow als individuele developer. Managed Agents Dreaming optimaliseert teams van agents die een gedeeld geheugen gebruiken.
Wat kost het en wie kan het nu gebruiken?
Dreaming is beschikbaar als Research Preview. Je moet toegang aanvragen via een formulier op claude.com. Het is nog geen open feature.
De kosten zijn eenvoudig: je betaalt de standaard API-tokentarieven voor het model dat je kiest. Bij Claude Opus 4.7 is dat $15 per miljoen input-tokens en $75 per miljoen output-tokens, omgerekend zo’n €13,50 en €67,50 bij de huidige wisselkoers. Bij Sonnet 4.6 betaal je een fractie daarvan: $3 en $15 per miljoen tokens, circa €2,70 en €13,50.
Daarbovenop betaal je voor Managed Agents een runtime-tarief van $0,08 per uur, zo’n €0,07. Dat is het tarief voor de agent-runtime, los van de tokenkosten.
Wat betekent dat concreet? Laten we een rekensom maken. Stel, je hebt een klantenservice-agent die per dag twintig sessies draait. Elke sessie genereert gemiddeld vijfduizend tokens aan transcripten. Een wekelijkse dream over honderd sessies (vijfhonderdduizend input-tokens) kost met Sonnet 4.6 circa €1,35 aan input plus een paar cent output. Dat is minder dan twee euro per week voor een agent die meetbaar beter presteert. Bij Opus 4.7, het grondigere model, loop je op naar zo’n €7 per week.
Niet verwaarloosbaar als je tientallen agents draait, maar in verhouding tot de kosten van de agents zelf (tientallen euro’s per dag bij intensief gebruik) is het een kleine toeslag. Als je bedenkt dat Harvey er een zesdubbele verbetering mee realiseerde, is de investering snel terugverdiend.
Let op: de usage-property op de dream-resource rapporteert het exacte tokenverbruik per dream. Je kunt de kosten dus nauwkeurig monitoren en bijsturen.
Tegelijk met Dreaming verdubbelde Anthropic de dagelijkse gebruikslimieten voor Pro- en Max-abonnees van vijf naar tien uur. Dat staat los van Dreaming, maar het helpt als je je agents intensief inzet voor taken als boekhouding of documentreview.
Harvey’s agents werden zes keer effectiever
Het sterkste bewijs voor Dreaming komt van Harvey, een Amerikaans AI-platform voor de juridische sector. Harvey bouwt agents voor complexe taken: langvormige juridische redactie, documentcreatie en contractanalyse.
Het probleem dat Harvey had is precies wat elke organisatie met AI-agents herkent. Agents die steeds opnieuw dezelfde workarounds moesten ontdekken. Hoe je een bepaald bestandsformaat moet verwerken. Welke tool het beste werkt voor een specifiek documenttype. Patronen die een menselijke medewerker na een week zou kennen, maar die een agent elke sessie opnieuw moest leren.
Met Dreaming onthouden Harvey’s agents die patronen. Het resultaat: het slagingspercentage steeg met factor zes. Niet door een beter model. Niet door betere prompts. Puur doordat institutionele kennis niet meer verloren ging.
Concreet betekende dat voor Harvey: agents die eerder vastliepen op bestandsconversies (van .docx naar PDF met specifieke juridische opmaak) hadden na Dreaming de workaround permanent in hun geheugen. Agents die de voorkeur van een specifieke partner voor bullet-point-samenvattingen boven lopende tekst steeds opnieuw moesten ontdekken, wisten het vanaf dag één. Kleine lessen, groot cumulatief effect.
Harvey is niet het enige voorbeeld. Netflix gebruikt de gerelateerde multiagent-orchestratie (op dezelfde dag gelanceerd) om build-logs van honderden builds parallel te analyseren met een lead-agent die het werk verdeelt over specialisten. En Wisedocs, een documentverwerker, draait met Outcomes (de derde nieuwe feature) nu vijftig procent snellere documentreviews doordat een apart beoordelingsmodel de output toetst aan vooraf gedefinieerde rubrics en de agent opnieuw laat proberen als het niet goed genoeg is.
Voor jou als Nederlandse ondernemer is dit herkenbaar. Negen op de tien Nederlandse directeuren draaien volgens het IBM CEO Study 2026 al AI-agents op schaal. Als jouw agents dagelijks klantgesprekken voeren, tickets verwerken of documenten analyseren, dan ken je het patroon: elke sessie begint je agent weer met een schone lei. Je developers besteden uren aan het bijwerken van system prompts met lessen die de agent zelf al had ontdekt, maar weer vergeten was.
Dreaming is het verschil tussen een stagiair die elke maandag opnieuw wordt ingewerkt en een collega die na drie maanden je bedrijf kent.
Wanneer past Dreaming in jouw workflow?
Dreaming is niet voor elke situatie zinvol. Het werkt het beste bij agents die herhaaldelijk dezelfde categorie taken uitvoeren. Klantenservice, documentreview, code-analyse, content-pipelines: hoe meer sessies, hoe meer patronen Dreaming kan herkennen.
Het werkt minder goed bij eenmalige taken (een éénmalige datamigratie heeft geen sessiegeschiedenis om van te leren), bij agents die elke keer een compleet ander type vraag krijgen (een generieke “vraag maar raak”-chatbot heeft geen herhalende patronen), of bij situaties waar de context zo snel verandert dat geleerde patronen binnen een week verouderd zijn.
Een goede vuistregel: als je agent minstens twintig sessies van hetzelfde type heeft afgerond, is Dreaming de moeite waard. Onder de tien sessies is er te weinig data om patronen uit te halen.
Anthropic raadt zelf aan om klein te beginnen: ”Start with a small batch of sessions and scale up once you’re satisfied with the curation quality.” Begin met tien sessies, bekijk het resultaat en schaal op als de kwaliteit je bevalt.
Een concreet voorbeeld. Stel, je runt een webshop met een AI-agent die retouraanvragen afhandelt. Na veertig sessies weet de agent dat bestellingen boven de honderd euro een manager-goedkeuring nodig hebben. Hij weet dat klanten uit België een ander retourformulier krijgen. En hij weet dat “verkeerde maat” de meest voorkomende retourreden is. Al die lessen staan in zijn memory, maar na driehonderd sessies is het een ongesorteerde brij.
Een wekelijkse dream comprimeert die brij tot een gestructureerd geheugen van honderd kernlessen. Het verwijdert de entries die achterhaald zijn sinds de retourprocedure vorige maand veranderde. En het ontdekt dat klanten op maandagochtend drie keer zo vaak retourneren als op vrijdagmiddag. Dat laatste wist niemand in je team. Je agent zag het in de data.
Of neem een ander scenario: je runt een AI-agent die facturen verwerkt voor je boekhouding. Na honderd sessies heeft de agent geleerd dat leverancier A altijd zijn BTW-nummer vergeet, dat leverancier B zijn facturen als .tiff stuurt in plaats van PDF, en dat het rekeningnummer op de factuur soms verschilt van het rekeningnummer in je CRM. Met Dreaming worden die lessen niet alleen bewaard, maar ook gerangschikt op frequentie. De meest voorkomende patronen komen bovenaan, zodat je agent bij de volgende factuur meteen weet waar hij op moet letten.
En tot slot een detail dat te mooi is om niet te noemen. Dreaming was al eerder per ongeluk ontdekt. Op 30 maart publiceerde Anthropic de broncode van Claude Code op npm, compleet met 59,8 megabyte aan source maps. In de 512.000 regels TypeScript vonden ontwikkelaars verwijzingen naar “Dream Mode” en “continuous background reasoning”. Zes weken later werd het officieel gelanceerd.
Simon Willison, die de conferentie live blogde, noemde Dreaming “particularly compelling” en beschreef een demo waarbij het systeem overnight een compleet draaiboek had geschreven voor een maanlanding-drone.
Wil je zelf aan de slag? Vraag toegang aan tot de Research Preview en begin met een kleine memory store en een handvol sessies. De kans is groot dat je agents patronen ontdekken die jij over het hoofd zag.
Veelgestelde vragen
Wat is Claude Dreaming?
Claude Dreaming is een feature van Anthropic waarbij AI-agents tussen sessies hun eigen werk terugkijken, patronen in fouten herkennen en de lessen opslaan in plain-text bestanden. De volgende sessie leest de agent die bestanden en presteert beter.
Wat is het verschil tussen Claude Memory en Claude Dreaming?
Memory slaat feiten op die je handmatig of tijdens een sessie vastlegt. Dreaming laat de agent zelfstandig zijn eigen sessies analyseren en patronen ontdekken, zonder dat jij daar iets voor hoeft te doen.
Hoeveel kost Claude Dreaming?
Je betaalt standaard API-tokentarieven. Met Sonnet 4.6 kost een wekelijkse dream over honderd sessies zo'n twee euro. Met Opus 4.7 komt dat op circa zeven euro per week. Daarbovenop betaal je 0,08 dollar per uur aan agent-runtime.
Kan ik Claude Dreaming nu al gebruiken?
Claude Dreaming is beschikbaar als research preview. Je kunt toegang aanvragen via het aanvraagformulier op de Anthropic-website. Het werkt met Claude Managed Agents en Claude Code.
Hoe effectief is Claude Dreaming in de praktijk?
Bij juridisch AI-platform Harvey steeg het slagingspercentage van agents met factor zes na het inschakelen van Dreaming, doordat institutionele kennis niet meer verloren ging tussen sessies.



