
In een enquête onder meer dan vijfhonderd developers koos 65 procent Codex als dagelijks hulpmiddel. Maar dezelfde groep beoordeelde de code van Claude Code in een blinde test als schoner en beter gestructureerd, in 67 procent van de rondes. Dat klinkt als een tegenstrijdigheid. Het is het niet. Het is precies de splitsing die het AI-programmeerlandschap op dit moment definieert: de tool die je het liefst opent is niet per se de tool die de beste code schrijft.
Overigens, het gaat snel. Tussen september 2025 en maart 2026 groeide Codex van vijf procent van Claude Code's gebruikersbasis naar veertig procent. In diezelfde periode steeg het aantal wekelijkse Codex-gebruikers naar meer dan twee miljoen. Wat er achter die verschuiving zit, is interessanter dan de cijfers zelf.
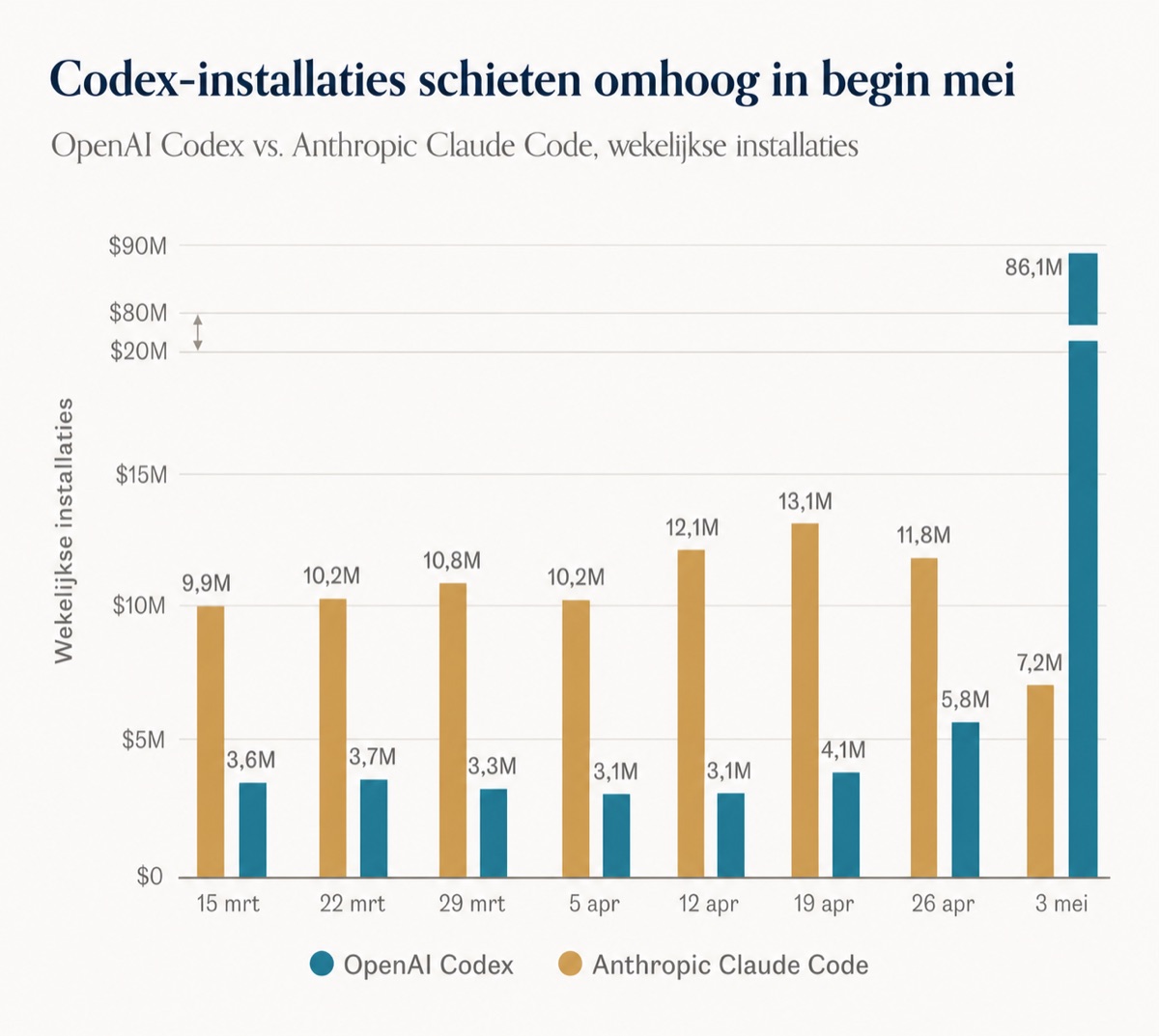
Waarom stappen developers over naar Codex?
Het korte antwoord: niet vanwege betere code, maar vanwege minder onderbrekingen. De grootste klacht over Claude Code in forumdiscussies is niet de kwaliteit van de output, het zijn de gebruikslimieten. Developers op het Pro-abonnement van twintig euro per maand melden dat ze na drie tot vijf intensieve prompts al tegen de limiet aanlopen. Een gebruiker op het Max 20x-abonnement van tweehonderd euro schreef: "Ik zit al vier maanden op Max x20 en loop regelmatig tegen het plafond aan."
Bij Codex speelt dat probleem nauwelijks. Op een vergelijkbaar abonnement melden gebruikers zelden dat ze tegen limieten aanlopen. De reden zit deels in de architectuur: Codex verbruikt voor dezelfde taak ongeveer vier keer minder tokens. Bij een gedocumenteerde Express.js-refactoring gebruikte Claude Code 6,2 miljoen tokens. Codex deed hetzelfde werk met 1,5 miljoen. Dat is niet alleen goedkoper, het betekent ook dat je langer kunt doorwerken zonder onderbreking.
Wacht even, vier keer minder tokens voor hetzelfde resultaat? Dat vraagt om nuance. Claude Code is uitgebreider in zijn uitleg, toont zijn redeneerstappen en vraagt vaker om bevestiging. Die uitgebreidheid levert betere code op bij complexe taken, maar kost ook meer. Het is het verschil tussen een collega die eerst drie vragen stelt en dan precies bouwt wat je bedoelde, en een collega die meteen begint en halverwege zegt: "Klaar, bekijk het maar."
Wat ging er mis bij Claude Code in maart en april?
De verschuiving naar Codex werd versneld door een periode van zes weken waarin Claude Code merkbaar slechter presteerde. Anthropic publiceerde op 23 april een openbare analyse waarin het bedrijf drie afzonderlijke problemen erkende die tegelijkertijd speelden.
Het eerste probleem: op 4 maart werd de standaard redeneerintensiteit verlaagd van hoog naar gemiddeld, om lange wachttijden te verminderen. Het resultaat was snellere maar dommere antwoorden. Het tweede probleem: op 26 maart veroorzaakte een fout in de contextcache dat Claude na een periode van inactiviteit bij elk volgend verzoek zijn eerdere redenering vergat. Niet eenmalig, maar bij elke beurt opnieuw. Het derde probleem: op 16 april werd een instructie toegevoegd die antwoorden moest inkorten tot maximaal 25 woorden tussen tool-aanroepen. Die beperking verslechterde de codeerkwaliteit met drie procent op de interne evaluatieset.
Omdat elk probleem een ander deel van het verkeer raakte op een ander moment, leek het voor gebruikers alsof Claude Code breed en onvoorspelbaar verslechterde. Een developer vatte het zo samen: "Het ging van de beste AI-tool die ik ken naar iets dat ik niet meer vertrouw voor de simpelste taken."
Anthropic loste alle drie de problemen op voor 20 april en verdubbelde de gebruikslimieten als compensatie. Maar het vertrouwenseffect was al zichtbaar in de ontwikkelaarsgemeenschap.
Hoe scoren ze op benchmarks?
De benchmarks vertellen twee verschillende verhalen, afhankelijk van welke je bekijkt.
Op SWE-bench Verified, de standaard voor het oplossen van echte GitHub-issues, scoort Claude Opus 4.7 met 87,6 procent hoger dan GPT-5.5 met circa 85 procent. Op SWE-bench Pro, de strengere variant, is het verschil groter: 64,3 procent voor Opus 4.7 tegenover 58,6 procent voor GPT-5.5. Voor complexe codeerproblemen levert Claude dus meetbaar betere oplossingen.
Draai je het om naar terminal- en infrastructuurtaken, dan kantelt het beeld. Op Terminal-Bench 2.0, dat meerstaps CLI-workflows meet, scoort GPT-5.5 met 82,7 procent ruim boven Opus 4.7 met circa 72 procent. Bij autonome systeemtaken, denk aan het aansturen van een browser of het uitvoeren van een volledige workflow zonder menselijke tussenkomst, domineert GPT-5.5 eveneens.
De conclusie uit de benchmarks bevestigt wat de ontwikkelaarsgemeenschap al aanvoelt: Claude Code is sterker op het oplossen van complexe codeproblemen, Codex is sterker op het autonoom uitvoeren van taken die meerdere stappen en tools combineren.
Waar wint Claude Code nog steeds?
Bij frontend-ontwerp en visueel werk is Claude Code voorlopig niet ingehaald. In een test waarin beide modellen vijf identieke UI-ontwerpen moesten bouwen met Tailwind CSS, toonde Opus 4.7 meer ontwerpvariatie. Het model varieerde lettergewichten, koos bewust kleuren per product en plaatste schaduwen contextafhankelijk. GPT-5.5 leverde werkende maar uniforme interfaces af, beschreven als "Tailwind UI starttemplates" in plaats van maatwerk.
Even voor de beeldvorming: bij een analytics-dashboard bouwde Claude functionele datavisualisatie met compacte tussenruimte en kleine trendgrafieken in de cellen, terwijl GPT-5.5 de nadruk legde op decoratieve elementen met opgesmukte cijfers. Bij een inschrijfpagina vergat GPT-5.5 de inloglink, een functionele misser die Claude niet maakte.
Die ontwerpkracht heeft een keerzijde. Een developer die een volledige React-applicatie bouwde, ontdekte dat Opus inline CSS door alle componenten strooide in plaats van Tailwind-klassen te gebruiken. Codex las eerst het hele project, ging bestand voor bestand door en converteerde alles naar Tailwind, inclusief geneste stijlen die Opus had gemist. De karakterisering van een developer: "Opus is de gretige ingenieur die snel levert maar technische schuld achterlaat. Codex is de introverte ingenieur die eerst de hele codebase leest voordat hij iets aanraakt."
Waar wint Codex?
Backend-architectuur, infrastructuur en autonome taken. Developers die grote monolithische codebases beheren, testsuites onderhouden en legacy-code migreren, kiezen in toenemende mate voor Codex. De reden: Codex respecteert projectinstructies in het AGENTS.md-bestand methodischer, werkt migraties af zonder gaten achter te laten en heeft minder supervisie nodig.
Het architectuurverschil speelt hier mee. Codex draait in afgesloten cloudomgevingen bij OpenAI, elk met een eigen kopie van je repository. Je geeft een opdracht, gaat verder met ander werk en bekijkt het resultaat later. Claude Code draait lokaal op je eigen machine, toont zijn redenering en vraagt op beslismomenten om goedkeuring.
Voor wie privacy of compliance-eisen heeft, is dat lokale draaien van Claude Code juist een voordeel: je code verlaat je machine niet. Maar voor productiviteit bij routinetaken wint het asynchrone model van Codex. Een developer op Hacker News beschreef het als: "Continu voor een scherm zitten om steeds op Enter te drukken is deprimerend. Codex laat me iets starten en verdergaan."
NVIDIA meldde dat GPT-5.5 in Codex debugsessies terugbracht van dagen naar uren en experimenten van weken naar een nacht, specifiek bij complexe codebases met meerdere bestanden.
Wat kost het in de praktijk?
Op papier liggen de API-prijzen dicht bij elkaar. Opus 4.7 kost vijf dollar per miljoen invoertokens en 25 dollar per miljoen uitvoertokens. GPT-5.5 kost vijf dollar per miljoen invoertokens en dertig dollar per miljoen uitvoertokens. Opus is dus zelfs iets goedkoper op uitvoer.
In de praktijk draait die vergelijking om. Omdat Claude Code per taak ongeveer vier keer meer tokens verbruikt, betaal je effectief meer. Volgens de analyse van DataCamp kostte een Express.js-refactoring op Claude Code circa 155 dollar, tegenover vijftien dollar op Codex. Zelfs als de code van Claude beter was, is een verhouding van tien tegen een moeilijk te rechtvaardigen voor routinewerk.
Bij abonnementen is het beeld vergelijkbaar. Claude Pro kost twintig euro per maand, Max 5x honderd euro, Max 20x tweehonderd euro. Codex biedt vergelijkbare prijspunten, maar gebruikers melden dat ze op een twintig-euro-abonnement bij Codex de hele dag kunnen werken, terwijl dat bij Claude Code na een ochtend intensief gebruik al op is.
De Opus 4.7-kwestie: beter maar moeilijker
De situatie wordt complexer door de ontvangst van Opus 4.7 zelf. Het model is objectief krachtiger dan zijn voorganger, Opus 4.6. Op een interne codeerbenchmark van 93 taken scoort het dertien procent hoger. Maar die kracht komt met gedragsveranderingen die developers frustreren.
De meest genoemde klacht: Opus 4.7 verdedigt zijn eigen code in plaats van correcties uit te voeren. Je wijst op een fout en het model legt uit waarom de fout eigenlijk geen fout is. Op eenvoudige taken waar 4.6 gewoon deed wat je vroeg, debatteert 4.7, aarzelt en verzint soms redenen om niet mee te werken.
De verklaring: Opus 4.7 volgt instructies veel letterlijker dan 4.6. Dat betekent dat vage prompts die eerder stilletjes werden gecorrigeerd, nu tot onverwachte resultaten leiden. Anthropic beschrijft het als een verschuiving van "behulpzame assistent" naar "precieze operator". Voor ervaren developers die gedetailleerde prompts schrijven, is dat een verbetering. Voor wie gewend was aan een model dat het vanzelf snapte, voelt het als een achteruitgang.
Daarbovenop verbruikt Opus 4.7 anderhalf tot drie keer meer tokens dan 4.6 voor dezelfde taak, deels door een tokenizer-wijziging die Engelse tekst twaalf tot achttien procent duurder maakt. Een deel van de gebruikers is daarom teruggestapt naar Opus 4.6, met het commando claude --model claude-opus-4-6.
De hybride aanpak die de meeste developers kiezen
De interessantste uitkomst uit de forumdiscussies is geen keuze, maar een combinatie. De zin "Codex voor toetsaanslagen, Claude Code voor commits" duikt steeds vaker op in developer-forums. Het betekent: gebruik Codex voor het grove werk, de routineklussen, de testreparaties en de parallelle taken. Gebruik Claude Code voor de architectuurbeslissingen, de cruciale wijzigingen en het werk waar je de code echt vertrouwt.
Een veelgenoemde workflow: laat Claude Code een feature bouwen, laat vervolgens Codex de code reviewen voor je samenvoegt. In een gedocumenteerde test vond Codex meerdere problemen in Claude Code's output die handmatige review had gemist. De omgekeerde test, Claude Code die Codex's output reviewde, leverde nul bevindingen op. Dat zegt iets over de systematische aanpak van Codex bij code-reviews.
Teams die beide tools inzetten, rapporteren een duidelijke taakverdeling:
- Claude Code: software-architectuur, frontend-ontwerp, complexe refactoring, planningsfase, werk dat diepe context vereist
- Codex: backend-routinewerk, infrastructuur, code-reviews, autonome achtergrondtaken, parallelle uitvoering
Wat betekent dit voor jouw werkwijze?
Als je vandaag een keuze moet maken, hangt die af van wat je de meeste uren per dag doet. Bouw je frontends, ontwerp je interfaces of werk je aan complexe architectuur waarbij je het model moet kunnen bijsturen? Dan is Claude Code met plugins als Superpowers voorlopig de sterkere keuze. Doe je vooral backend-werk, beheer je infrastructuur of wil je taken starten en later het resultaat bekijken? Dan levert Codex met zijn doelen-workflow meer op per geïnvesteerd uur.
De duurste fout is trouw blijven aan een tool uit gewoonte terwijl je workflow beter past bij de ander. Developers die beide tools probeerden en de taken verdeelden op basis van sterke punten, melden consistent hogere productiviteit dan wie bij een enkele tool bleef.
Drie dingen die je deze week kunt doen:
- Probeer de gratis laag van Codex voor een standaard herschrijving die je normaal in Claude Code doet, en vergelijk het tokenverbruik
- Check je Claude Code-model: draai je op Opus 4.7 en loop je tegen gedragsproblemen aan? Probeer
claude --model claude-opus-4-6voor taken waar je het oude gedrag verkiest - Stel een AGENTS.md-bestand op voor je projecten: Codex respecteert deze instructies en past zijn stijl aan op je codebase, vergelijkbaar met hoe Claude Code's CLAUDE.md werkt



