Vorige maand liet ik twee losse Claude-sessies dezelfde codebase reviewen. Sessie A vond de authenticatie-flow solide maar zag problemen in de databaselaag. Sessie B vond de database prima maar maakte zich zorgen over de authenticatie. Twee keer dezelfde vraag, twee totaal verschillende diagnoses. Dat is geen bug, dat is hoe grote taalmodellen werken: elk gesprek begint met een schone lei en een eigen interpretatielens.
In de gezondheidszorg hebben ze daar een oplossing voor. Voordat een chirurg opereert, is er een multidisciplinair overleg (MDO) waarin bijvoorbeeld een radioloog, een oncoloog, een anesthesist en een verpleegkundige elk vanuit hun eigen expertise naar dezelfde patiënt kijken. Niet omdat één arts het fout heeft, maar omdat blinde vlekken onvermijdelijk zijn als je maar vanuit één perspectief kijkt.
Claude Code heeft sinds begin dit jaar een experimentele feature die precies dat doet voor code: agent teams. Ik gebruik het inmiddels bijna dagelijks bij UnicornAI en Digital Impact, en het heeft fundamenteel veranderd hoe ik naar code-reviews en architectuurbeslissingen kijk.
Waarom één AI-gesprek niet genoeg is
Stel, je vraagt Claude om je betaalflow te reviewen. Claude leest de code, identificeert drie risico's, en geeft je een rapport. Je voelt je gerust. Maar open een nieuw gesprek, geef dezelfde code, en de kans is groot dat je drie andere risico's krijgt. Niet per se betere of slechtere, maar andere.
Dat komt doordat een LLM bij elke sessie opnieuw begint. Er is geen geheugen van eerdere reviews, geen vaste checklist, geen "vorige keer keek ik naar SQL-injection, dus nu focus ik op XSS". Elke sessie is een verse arts die de patiënt voor het eerst ziet.
Bij triviale taken maakt dat niet uit. Maar bij security-audits, architectuurkeuzes of complexe refactors wil je niet afhankelijk zijn van welke toevallige focus een enkel gesprek heeft. Je wilt hoor en wederhoor.
Wat agent teams zijn en hoe ze werken
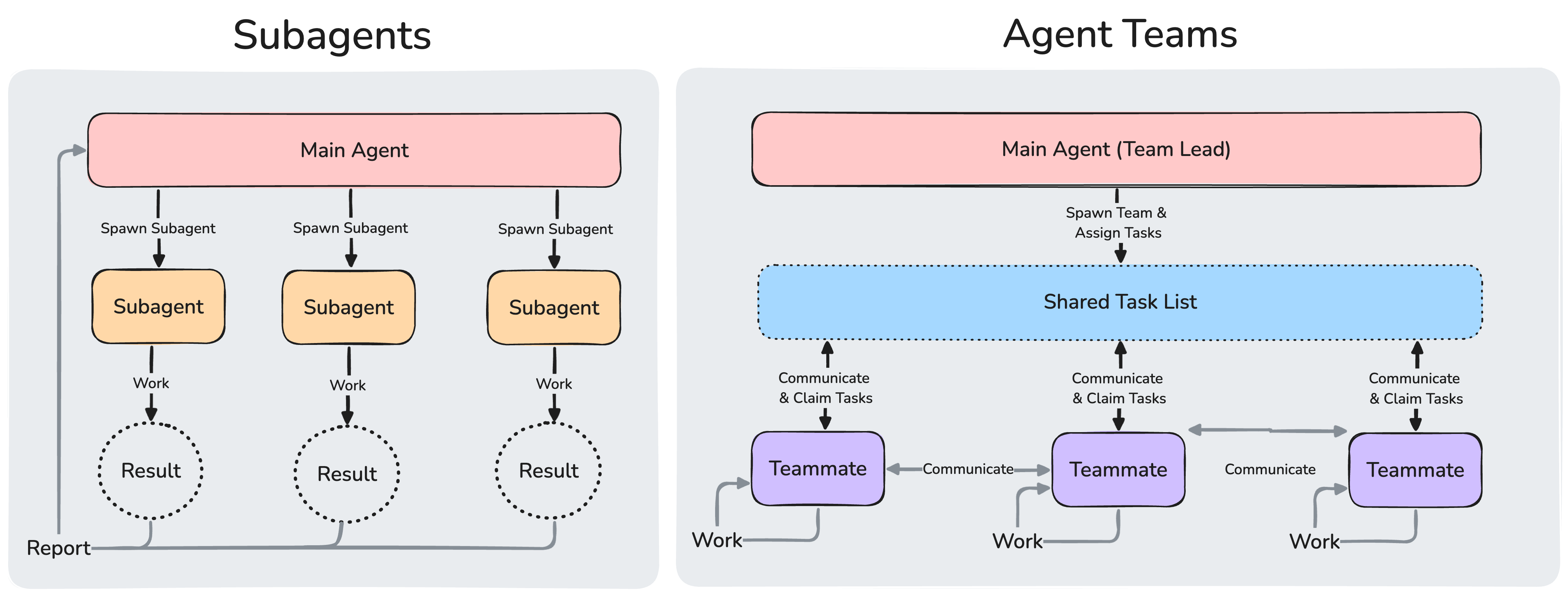
Agent teams zijn geen chatvensters die je naast elkaar openzet. Het zijn meerdere volwaardige Claude Code-sessies die tegelijkertijd draaien, elk met een eigen contextvenster, en die onderling kunnen communiceren via een gedeelde takenlijst en een berichtensysteem.
Je hebt een lead (de hoofdsessie waar jij mee praat) en teammates (de parallelle sessies). De lead verdeelt werk, de teammates voeren uit, en iedereen kan elkaar berichten sturen. Denk aan een Slack-groep waar vijf specialisten tegelijk aan hetzelfde project werken, maar dan zonder de drie dagen vertraging.
De feature is experimenteel en staat standaard uit. Activeren doe je door deze environment-variabele te zetten:
export CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1
Of permanent in je settings.json:
{
"env": {
"CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1"
}
}Hoe ik het dagelijks inzet
Bij UnicornAI gebruik ik agent teams voor drie terugkerende patronen. Het eerste is de meest waardevolle: de parallelle code-review met verschillende brillen.
In plaats van Claude te vragen "review deze code", zeg ik:
Maak een team van drie reviewers voor de betaalmodule: - Eén focused op security (OWASP top 10, input validation, auth) - Eén focused op performance (N+1 queries, caching, response times) - Eén focused op onderhoudbaarheid (naming, structuur, testbaarheid) Laat ze elk onafhankelijk reviewen en dan elkaars bevindingen challengen.
Dat laatste deel is cruciaal: elkaars bevindingen challengen. De security-reviewer zegt misschien "deze input moet gesanitized worden". De performance-reviewer reageert: "die sanitization voegt 200ms toe per request, is dat acceptabel op deze plek?" En de onderhoudbaarheids-reviewer vraagt: "waarom zit die sanitization niet in een middleware in plaats van in elke controller?" Dat gesprek tussen de agents levert inzichten op die geen van de drie alleen had gevonden.
Het tweede patroon: concurrent debugging. Bij een hardnekkige bug laat ik drie tot vijf agents elk een andere hypothese onderzoeken. Agent A checkt of het een race condition is. Agent B kijkt naar de caching-laag. Agent C onderzoekt of er een database-migration mist. Ze delen hun bevindingen onderling en proberen elkaars theorieën te weerleggen. In de praktijk is de bug binnen tien minuten gevonden in plaats van een uur rondzoeken in één sessie.
Het derde patroon: cross-layer features. Eén agent bouwt de API-endpoint, een ander de frontend-component. Ze stemmen het contract (request/response format) onderling af via berichten, en bouwen parallel. Voor features die normaal achter elkaar gaan (eerst backend, dan frontend) halveert dit de doorlooptijd.
Automatiseren met LaunchAgents
Het wordt pas echt interessant als je team-reviews automatiseert. Bij UnicornAI draait er een nachtelijke security-audit als agent-team via een macOS LaunchAgent. Elke nacht om 03:00 start een headless Claude-sessie die drie teammates spawnt: een security-reviewer, een dependency-checker en een OWASP-auditor. Ze reviewen de codebase onafhankelijk en genereren een rapport dat 's ochtends in mijn inbox ligt.
De LaunchAgent ziet er zo uit:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN"
"http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>com.unicornai.security-audit</string>
<key>ProgramArguments</key>
<array>
<string>/bin/bash</string>
<string>/Users/jouwnaam/bin/security-audit.sh</string>
</array>
<key>StartCalendarInterval</key>
<dict>
<key>Hour</key><integer>3</integer>
<key>Minute</key><integer>0</integer>
</dict>
</dict>
</plist>En het shell-script dat het team aanstuurt:
#!/bin/bash export CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1 cd "$HOME/Projects/mijn-project" claude -p " Maak een team van drie agents voor een nachtelijke security-audit: 1. Security: check OWASP top 10, bekende kwetsbaarheden, input validation 2. Dependencies: scan package.json/composer.json op verouderde of kwetsbare packages 3. Config: controleer .env, headers, CORS, CSP, exposed secrets Laat ze onafhankelijk werken. Combineer de bevindingen in één rapport. Schrijf het rapport naar audit-report.md met datum, ernst per finding, en concrete fix-suggesties. " --model claude-sonnet-4-6 \ --dangerously-skip-permissions \ 2>&1 >> logs/security-audit.log
De audit kost op Sonnet 4.6 met drie agents ongeveer drie tot vier keer zoveel tokens als een enkele sessie. In de praktijk minder dan een euro per run. Voor een nachtelijke security-scan die drie onafhankelijke perspectieven oplevert is dat verwaarloosbaar.
Wat het kost en wanneer het niet past
Agent teams zijn niet gratis. Drie teammates betekent drie keer de context, dus ruw drie tot vier keer de tokenkosten. Een review die normaal een euro kost, wordt drie tot vier euro. Voor een dagelijkse security-audit of een complexe refactor is dat het waard. Voor het fixen van een typo niet.
Vuistregel: als je de taak in één gesprek in minder dan vijf minuten afhandelt, gebruik dan geen team. Als je merkt dat je dezelfde vraag opnieuw stelt in een nieuw gesprek omdat je het antwoord niet vertrouwt, dan wil je een team.
Andere beperkingen om te weten:
- Geen persistentie. Agent teams overleven een sessie niet. Als Claude Code crasht of je de terminal sluit, moet je het team opnieuw opzetten. Dat maakt het ongeschikt voor projecten die dagen duren.
- Bestandsconflicten. Twee agents die tegelijk hetzelfde bestand bewerken veroorzaken problemen. Verdeel het werk zo dat elke agent zijn eigen bestanden heeft.
- Alleen terminal. De VS Code-extensie ondersteunt agent teams niet betrouwbaar. Gebruik de CLI.
Het MDO voor je codebase
De kern is simpel. Eén perspectief geeft je een mening. Meerdere perspectieven geven je een diagnose. Net als een chirurg die niet opereert voordat de radioloog, de patholoog en de anesthesist hun oordeel hebben gegeven, wil je niet deployen op basis van één AI-review die toevallig je blinde vlek deelt.
Werk je met meerdere agents, dan wordt elke agent een eigen specificatie. Hoe je die opbouwt lees je in de negen dimensies waarmee je een AI-agent bouwt.
Agent teams kosten meer tokens en meer setup dan een enkel gesprek. Maar ze vangen precies het probleem op waar iedereen die serieus met AI-code werkt tegenaan loopt: dat de kwaliteit van je output afhangt van welk toevallig perspectief je sessie die dag heeft. Met drie tot vijf agents die elkaar challengen maak je van een enkel oordeel een multidisciplinair overleg. En dat overleg is, net als in het ziekenhuis, bijna altijd beter dan de beste individuele specialist.