claude-mem: blijvend geheugen tussen Claude Code sessies
Wat deze skill doet
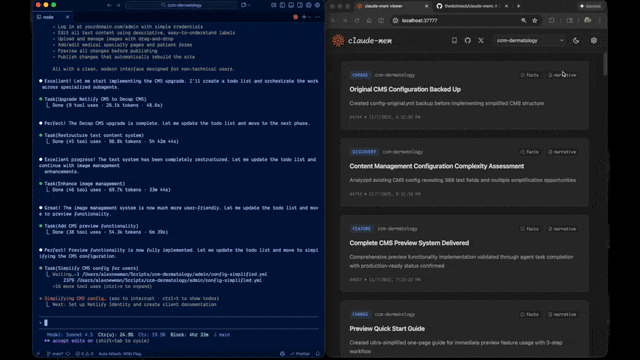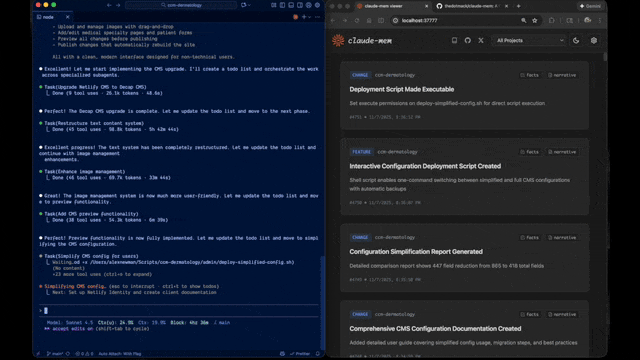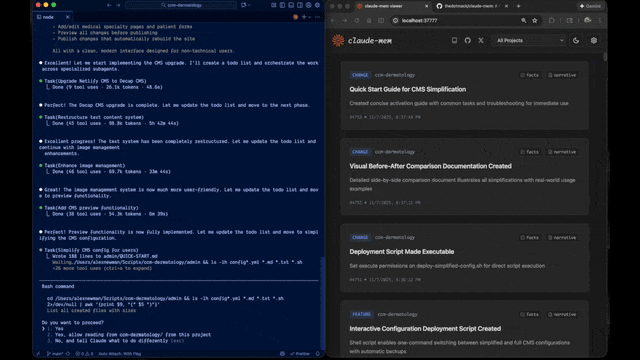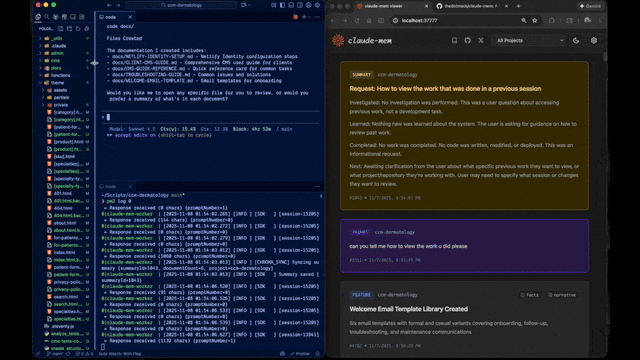
claude-mem geeft Claude Code blijvend geheugen tussen sessies. De plugin draait op de achtergrond, vangt automatisch op wat er gebeurt — beslissingen, tool-gebruik, conclusies — en injecteert relevante stukken in je volgende sessie. Gemaakt door Alex Newman (thedotmack), AGPL 3.0, op dit moment versie 12.0, ~46.000 GitHub-sterren.
Het probleem dat het oplost is reëel: elke nieuwe Claude Code-sessie start blanco. Je bent de eerste tien minuten bezig met "hier is het project opnieuw". Die frictie verdwijnt. Maar het komt met waarschuwingen die je serieus moet nemen.
Hoe het werkt
Bij installatie (npx claude-mem install) haakt de plugin in op vijf Claude Code session-lifecycle events. Alles wat Claude ziet en doet wordt lokaal opgeslagen en gecomprimeerd tot semantische samenvattingen. Bij een volgende sessie zoekt claude-mem relevante oude observaties op basis van je vraag en stuurt die mee als context — niet alles tegelijk.
- Web-viewer op
localhost:37777: blader door alles wat is opgeslagen - Zoek-skill: vraag in natuurlijke taal "hoe zat het ook alweer met die auth-flow?"
- Privacy-tags: alles tussen
<private>-tags wordt niet opgeslagen - Cross-tool: memory uit Claude Desktop is beschikbaar in Claude Code, Gemini CLI, OpenCode en OpenClaw
Wat gebruikers rapporteren
YUV.AI (over de onboarding-ervaring): "Een gebruiker stond op het punt claude-mem in week één te deïnstalleren omdat sessies sneller het context-limit raakten dan daarvoor. Na ongeveer een week zakte de ruis, en sessies gingen langer mee dan vóór de plugin."
Augment Code: "De compressie houdt tokenkosten hanteerbaar. De drie-laagse MCP-workflow geeft ongeveer 10x token-besparing door te filteren voordat je details ophaalt."
HN (skeptisch): "Nothing works better than simply keeping my own library of markdown files." Een andere gebruiker vraagt zich af of er benchmarks bestaan die bewijzen dat de output-kwaliteit daadwerkelijk verbetert.
HN (enterprise): "We have contracts with OpenAI, Anthropic and Google with isolated hosting requirements — we won't send proprietary code to third-party servers."
Serieuze incidenten
Twee bugs in de issue-tracker zijn het noemen waard als je claude-mem overweegt:
- Issue #1090: een worker-daemon leak spawnde 280 orphaned
claude-sonnet-4-5processen, 65 GB RAM over 10 dagen, ~$183/dag aan onbedoelde Sonnet-spend. Een gebruiker meldde honderden dollars in onverwachte API-kosten - Issue #213: 184 orphaned ChromaDB-processen, 16 GB RAM in 19 uur, getriggerd door een corrupte ONNX-model
- Security-audit februari 2026: de port-37777 HTTP API had geen authenticatie en was standaard gebonden aan 0.0.0.0 — elk lokaal proces kon alle observaties lezen. High risk
Tips die werken
- Patroon: zoek → filter → ophalen. Nooit
get_observationszonder eerst te filteren. Daar komt de 10x token-besparing vandaan <private>-tags rondom secrets voordat ze de compressie-pipeline raken. Dit is de enige pre-capture filter- Zet ChromaDB uit, houd FTS5 aan. Meerdere community-writeups raden aan op de SQLite+FTS5 backend te blijven om de ChromaDB subprocess-leak te vermijden
- Bind de web-viewer aan 127.0.0.1, niet 0.0.0.0. Draai claude-mem niet op cloud-VMs of gedeelde dev-boxes
- Combineer met een handgeschreven
CLAUDE.mdin plaats van die te vervangen. claude-mem vangt episodisch geheugen;CLAUDE.mdblijft je conventie-document
Alternatieven
- memsearch (Milvus/Zilliz): markdown-first, positioneert zich als de lichte variant voor wie claude-mem "overly complex" vindt
- A-MEM: zelf-evoluerende ChromaDB-notes, Show HN januari 2026
- Letta/MemGPT: vervangt de agent zelf, vereist cloud-inference — zwaarder
- Mem0, langmem, zep, supermemory, openmemory: API-wrappers, niet plugin-native
Hoe claude-mem zich onderscheidt
Het verschil met ChatGPT's ingebouwde memory of Cursor's memory zit in drie dingen: het is lokaal-first (geen cloud-storage), het hooks direct in Claude Code's session-lifecycle (in plaats van een API-wrapper), en het werkt cross-tool. Dat laatste is uniek — geen enkele van de grote alternatieven deelt memory tussen Claude Desktop en Claude Code.
Wanneer je hem inzet
- Langlopende projecten waar context over dagen of weken ertoe doet
- Debuggen waar gisteren's conclusies niet opnieuw uitgezocht hoeven te worden
- Wisselen tussen Claude Desktop, Claude Code en Gemini CLI op hetzelfde project
- Onderzoek waar de geschiedenis van bevindingen telt
- Niet geschikt voor: gedeelde dev-VMs (port 37777 issue), repo's met strikte hosting-eisen, of wie al tevreden is met hand-geschreven markdown-notes
Prompt template
# Quick install via npm npx claude-mem install # Of via Claude Code plugin marketplace /plugin marketplace add thedotmack/claude-mem /plugin install claude-mem # Zoeken in memory tijdens een sessie /mem-search "hoe hebben we de auth flow opgezet?" # Iets expliciet NIET opslaan <private>password is hunter2</private>
Voorbeeld
Input
# Sessie 1 (maandag) "We hebben besloten JWT tokens te signen met RS256 in plaats van HS256, want we willen de public key kunnen delen met microservices."
Output
De volgende sessie (bijv. dinsdag), zonder enige actie van jou:
[Context uit eerdere sessies]
Auth-architectuur: JWT tokens gesignd met RS256 (niet HS256). Reden: public key wordt gedeeld met microservices. Keys opgeslagen in AWS Secrets Manager onder/auth/jwt/prod.
Vraag je nu "hoe zat het ook alweer met die microservice auth?" dan pakt Claude die context direct. Geen "ik weet het niet meer" of verkeerde gok. De web-viewer op localhost:37777 toont alle observaties die zijn opgeslagen, met timestamp en source.